
티스토리 뷰
참고 서적 Computer Networking, A Top Down Approaching
1990년 이전만 하더라도 HTTP는 주로 학회, 연구 또는 대학생들이 원격 호스트에 접속하거나 로컬 호스트에서 원격 호스트에서 파일을 전송하거나 다운로드 받거나, 뉴스를 보내거나 받을 때, 또는 이메일을 받거나 보낼 때 사용했습니다. 1990년 초에 world wide web이라는 새로운 어플리케이션이 나왔고, 대중들의 관심을 얻었습니다. 그 후 web은 드라마틱하게 변했고, 현재도 변화하고 있습니다. 사용자들은 web을 이용해 업무 안 쪽 환경과 바깥 쪽 환경과 인터랙트하고 있습니다.
대다수의 사용자들에게 web의 매력이란 필요에 의해서 동작하는 것이라는 점입니다. 전통적인 tv나 radio같은 매체는 컨텐츠를 활용하기 위해선 반드시 컨텐츠 제공자가 컨텐츠를 제공할 때 반드시 그것에 맞추어야하는 반면에, Web을 통해 컨텐츠를 얻는 방법은 사용자가 매우 쉽게 접근 가능합니다. 누구나 매우 저렴한 비용으로 컨텐츠 제공자가 될 수 있습니다. 2003년 이후로, Web은 매우 멋진 어플리케이션을 제공하고 있습니다. 예로 Youtube, Gmail, Facebook 입니다.
overview of HTTP
HTTP는 웹의 어플리케이션 계층 프로토콜입니다. 웹의 심장부라고 할 수 있습니다. HTTP는 두 프로그램으로 이루어져있습니다. 클라이언트와 서버입니다. 클라이언트와 서버는 다른 end-system에서 동작하며, HTTP 메시지를 이용하여 서로 메시지를 교환합니다. HTTP는 메시지 구조 및 클라이언트와 서버가 어떻게 메시지를 교환할지 정의합니다.
Web Page는 오브젝트로 이루어져있습니다. 오브젝트란 어떤 파일같은 것인데, HTML 파일, JPEG image, java applet, video clip 따위의, 단일 URL로 가르킬 수 있는 특징이 있습니다. 대부분의 웹페이지는 base HTML file과 몇 개의 참조 오브젝트로 이루어져있습니다. 웹 페이지가 HTML text와 JPEG image가 5개가 있다면, 웹 페이지는 6개의 오브젝트를 가지고 있는 것입니다.
HTTP는 TCP라는 전송 계층 프로토콜을 이용합니다. HTTP 클라이언트는 먼저 서버에 TCP 연결을 요청합니다. 연결이 성공되면, 클라이언트와 서버는 socket interface를 이용하여 TCP에 접근합니다. 클라이언트는 HTTP 리퀘스트를 보내고 리스폰스를 받고, 서버는 HTTP 리퀘스트를 받고 리스폰스를 보냅니다. 각 호스트가, socket interface를 통해 메시지를 보냈다면 그 이후의 메시지를 핸들링 하는 일은 HTTP의 영역이 아닌 TCP의 영역입니다. HTTP는 TCP가 할 일인, lost data나 loss recover 또는 reordering of data 일은 신경쓰지 않아도 됩니다. 그런 일들은 HTTP 밑 네트워크 계층인 TCP 계층의 일입니다.
HTTP는 stateless protocol 으로서, 한 서버가 여러 클라이언트를 상대할 수 있도록 효율적인 리소스 관리를 위해 이 방식을 채택하고 있습니다. 서버가 클라이언트를 상대로 통신할 때 어떠한 정보도 저장하지 않는 방식을 채택하는데, 같은 클라이언트가 동일한 리퀘스트를 날리더라도 서버는 새로운 클라이언트의 새로운 리퀘스트를 처리하 듯이 동작합니다.
그리고 웹 서버는 항상 고정된 아이피를 가지고 일반적으로 수백만개의 클라이언트의 리퀘스트를 대응할 수 있습니다.
Non-persistent 와 Persistent
인터넷 어플리케이션에서, 클라이언트와 서버 간의 통신을 수행하는데, 이는 일정시간 수행하여 몇 개의 리퀘스트 및 리스폰스로 이루어져있다. 어플리케이션의 성격에 따라 리퀘스트는 연달아 또는 특정 기간동안 일정하게 또는 간헐적으로 수행된다. 클라이언트와 서버는 TCP를 통해 통신하고 있는데, 어플리케이션 개발자는 TCP를 non-persistent 또는 persistent하게 이용할 지 결정할 수 있다. 용어를 풀어서 얘기하자면, 각 각의 리퀘스트/리스폰스를 분리된 TCP 연결로 처리할 지 또는 같은 TCP 연결에서 리퀘스트/리스폰스를 처리할 지 결정할 수 있다. 이는 HTTP의 stateless protocol과 다른 얘기다. HTTP는 TCP의 상위 protocol이며, Non-persistent/persistent의 성격은 TCP의 특징이다. 참고: https://stackoverflow.com/questions/13230789/why-is-http-protocol-stateless-if-it-can-deal-with-persistent-connections
Why is HTTP protocol stateless if it can deal with persistent connections?
The HTTP protocol is stateless, but I found this on the Kurose-Ross book: The default HTTP method is with persistent connections and pipeling. This means that it can handle multiple requests,...
stackoverflow.com
HTTP/1.1~는 default로 persistent를 채택하고 있으나 개발자가 손쉽게 바꿀 수 있다. non-persistent의 단점으로는 각 리퀘스트에 대해 새 TCP 연결을 하는데에 있다. 각 연결들 마다 TCP 버퍼가 할당되고, TCP 변수들이 클라이언트 및 서버에 선언되어야 한다. 이는 동시에 여러 클라이언트에서 요청되는 리퀘스트를 처리하는 웹서버 입장에서는 상당한 짐이 된다. 그리고 새 TCP 연결을 하는데에 있어, TCP를 수립하기위한 three-way handshake용 RTT가 있으므로 delivery delay가 발생할 수 있다.
HTTP Message Format
HTTP Request message 및 HTTP Response message는 규격이 있다. HTTP Request messsage 에서 Method field가 있는데, GET, POST, HEAD, PUT 그리고 DELETE 값이 들어갈 수 있다. 그 외는 생략합니다.
User-Server Interaction: Cookies
HTTP는 Stateless이다. 그러나 Web site는 사용자 개개인의 정보를 식별해야 할 이유가 있다. 사용자의 접근을 제한하거나, 특정 컨텐츠를 사용자에게 제공하고 싶을 때가 있다. 그 때는 HTTP는 cookie를 쓴다. 사용자가 웹 사이트에 접근하였을 때, 서버가 고유 번호를 부여하고, 데이터베이스에 entry를 만든다. 그리고 웹 서버에서 HTTP 리스폰스에서 Set-cookie 헤더에 해당 고유번호를 저장하여 넘겨준다.

브라우저는 HTTP 리스폰스 메시지를 받은 뒤, Set-cookie 헤더를 본다. 그리고 브라우저는 cookie 파일에 한 줄을 추가하는데, 이 한 줄에는 서버의 호스트이름과 Set-cookie 헤더에 포함된다. 쿠키파일안에는 여러 사이트에 대한 쿠키 정보가 포함되며, 해당 사이트에 접속할 때는, 쿠키파일에서 해당 사이트에 대한 Cookie 정보를 가져와 HTTP 리퀘스트의 헤더에 포함하여 보낸다. 그러면 서버에서, 사용자의 Cookie를 확인하여 적절한 컨텐츠를 제공해준다. 사용자가 만약 회원가입을 한 상태라면, 사용자의 이름, 이메일, 주소, 우편번호, 신용카드 정보 등이 웹 서버의 데이터베이스에 저장 될 수 있다. 이전에 이 사이트에서 주로 갔던 페이지 등도 저장될 수 있는 것이다. 사용자들은 그래서 재 방문하였을 때 해당 정보를 재 입력할 필요가 없는 것이다.
간략하게, Cookies는 사용자를 identify하는데 사용할 수 있는 것이다.
Web Caching
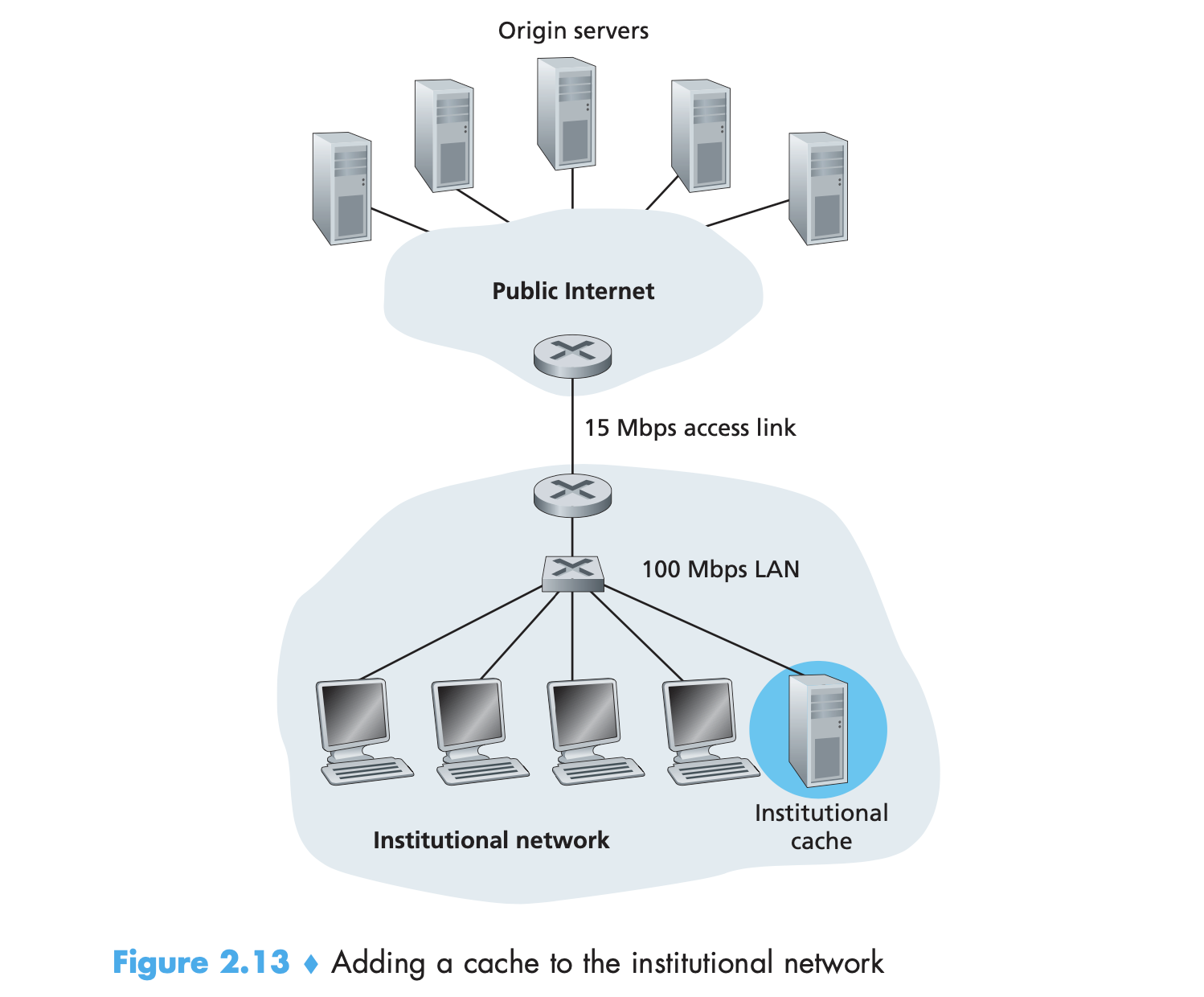
Web Cache란, origin 웹 서버를 대신하여 HTTP request에 대해 응답하는 네트워크 entity이다. proxy server라고도 불린다. 웹 캐시는 스스로의 disk storage를 가지며, 최근 요청받은 objects의 복사본을 그 저장소에 가지고 있는다. 클라이언트가 특정 HTTP Request를 한경우 Web Cache에서 해당 object를 보유하고 있다면 Web Cache 단에서 클라이언트로 전송한다. 만약 없는 경우, Web Cache는 서버에게 요청하고, 받은 object를 클라이언트로 전송 및 스토리지에 복사본을 보관한다.
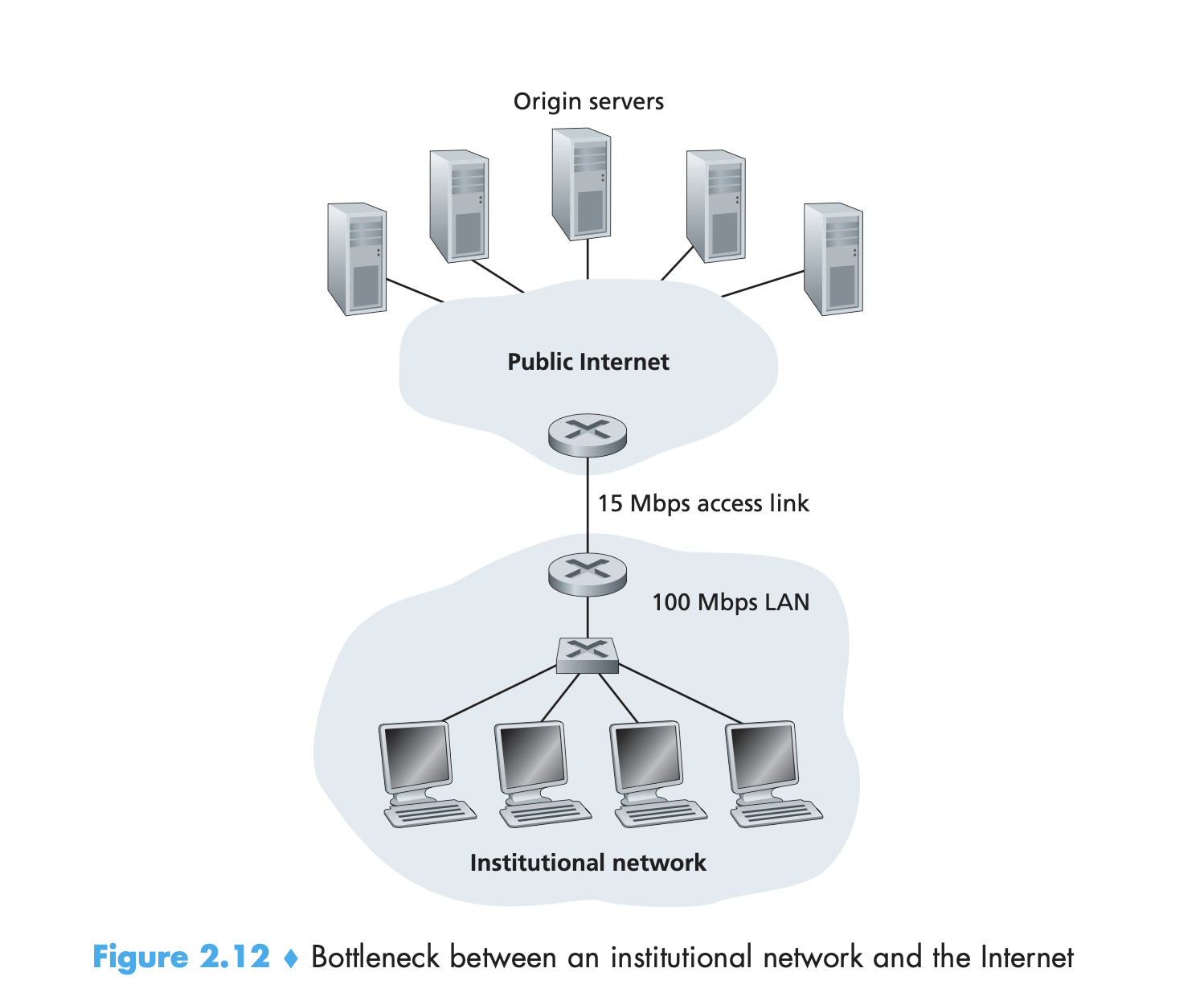
Web cache가 인터넷에서 사용되는 이유는 두가지 이다. web cache는 대체적으로 클라이언트 요청에 대한 응답시간을 줄여준다. 특히 클라이언트-서버간의 대역폭 병목이 클라이언트-웹 캐시간 대역폭 병목 보다 더 심한경우가 해당할 수 있다. 클라이언트-웹 캐시간 빠른 속도를 지원하는 연결이 있는경우, 클라이언트는 요청에 대해 빠르게 응답받을 수 있다. 두번째로는, web cache가 대체적으로 조직적인 네트워크에 대해 인터넷 접근 혼잡도를 줄여준다는 점이다. 혼잡도를 줄임으로 인해, 조직은 (회사나 대학) 대역폭을 업그레이드 하지 않아도 되고 비용을 절약할 수 있다. 또한 웹 캐시는 인터넷이란 전체의 시스템의 혼잡도를 줄이므로, 모든 참가 어플리케이션의 성능을 향상할 수 있다.
웹캐시의 이점 insight는, 긴 설명보다 아래의 그림으로 대체한다.
'네트워크' 카테고리의 다른 글
| 네트워크 보안- 대칭키/비대칭키과 SSL (0) | 2021.11.15 |
|---|---|
| 인강) 네트워크 계층 (0) | 2021.08.17 |
| 중간 과제) socket 프로그래밍 (0) | 2021.05.15 |
| 인강 ) 전송계층(3) - TCP(2) (0) | 2021.05.05 |
| 인강 ) 전송계층(2) - TCP (0) | 2021.05.04 |
- Total
- Today
- Yesterday
- Simulation
- 데이터 중심 애플리케이션 설계
- 최단경로 알고리즘
- 이산수학
- 시뮬레이션
- rosen
- 백준
- 아레나 시뮬레이션
- 자바스크립트 예제
- arena simulation
- 그라파나
- 로젠
- paul wilton
- flutter
- Grafana
- Discrete Mathematics
- beginning javascript
- 자바스크립트
- grafana cloud
- 대규모 시스템 설계 기초
- 항해99
- Propositional and Predicate Logic
- 명제논리
- Arena
- javascript
- 이산 수학
- 아레나시뮬레이션
- 엄청난 인내심과 시뮬레이션을 위한 아레나 툴
- 아레나
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |