
티스토리 뷰
강의 url www.kocw.or.kr/home/cview.do?mty=p&kemId=1169634
컴퓨터네트워크
인터넷을 동작시키는 컴퓨터네트워크 프로토폴을 학습한다.
www.kocw.net
1) TCP flow control에 대해 설명할 수 있다.
2) TCP connection management
TCP flow control

TCP의 flow control이란, 두 Host 간 sender/receiver buffer의 capa에 맞게 통신 속도를 조절하는 것 이다.
Host에서 receive를 수행할 때 receive buffer에서 Application Layer로 이동한다. Application Layer에서 프로그래밍 과제를 수행했던 것을 기억해보자. socket으로 부터 read를 수행하는 것은, Transport Layer에서 저장하고있는 receive buffer에서 존재하는 data가 Application Layer로 전달되는 것이다. flow control은 receiver capa만큼 data의 전달률(처리율 throughput, 단위: bytes/sec) 을 결정하는 것이다. flow control은 segment의 header에 담기는 recevie buffer 필드를 참조하여 결정된다.

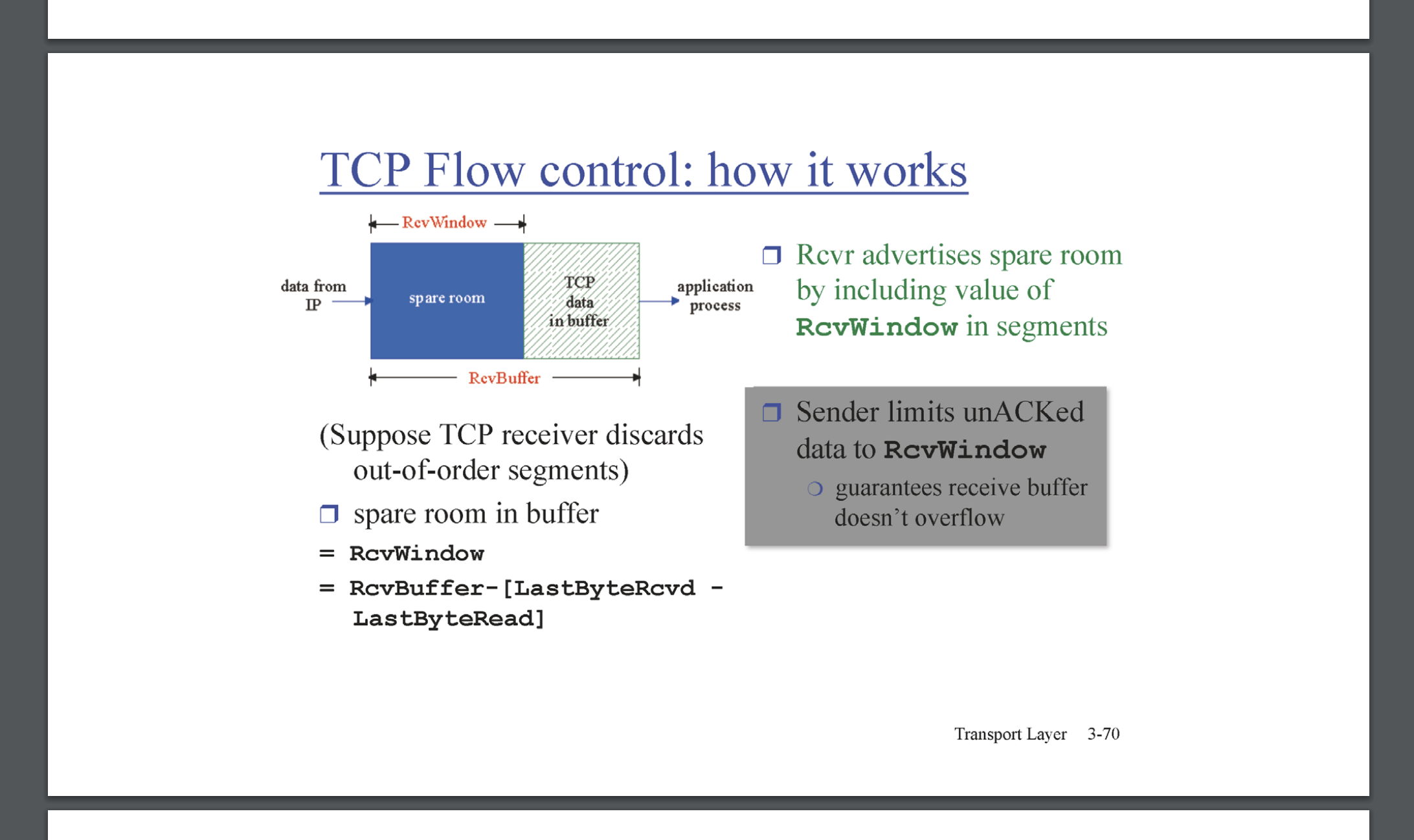
flow control의 기능은 중요하나, 구현이 매우 단순하다. receive buffer의 여분 buffer 만큼 크기만큼, 수용이 가능한 것 이다. 위 예에선 여분의 buffer를 RcvBuffer - [LastByteRcvb - LastByteRead]라고 표현했다. 이 정도면 설명이 충분하다. 마이너한 부분을 다뤄보자면, 만약 Host B의 여분의 received buffer가 없어 zero 를 담아 보냈다고 하자. 그렇다면 상대 Host A는 보내지 말아야하나? 만약 그렇다면, 그 후 Host B의 Application Layer에서 received buffer에서 data를 충분히 읽어가서 충분한 spare 공간이 생겼다 하더라도, Host A는 어떻게 알 것인가? Host A는 주기적으로 segment를 보내되, data 부분을 최소화하여 보낸다. Host B가 증가한 Ack을 보내면, 여분의 공간이 생겨 해당 data를 읽었다는 신호를 받을 수 있기 때문이다.
TCP Connection Management

TCP를 활용한 통신을 수행하기 위해서, sender buffer, receiver buffer를 활용한다는 것은 앞서 계속 설명해왔다. 그리고 Seq, ACK도 사용된다. Host A에서의 sender buffer는 상대 B의 Ack과 A의 Seq을 tracking하며 수행되고, Host A의 recevier buffer에서는 상대 B의 seq과 A의 ACK을 tracking 하며 수행 된다. TCP의 segment가 활발히 통신되기 전에, 최초의 Connection의 establish에서는 최소한의 정보 Seq만이 사용되며, 이 것을 활용하여 모든 정보가 동기화Sync가 되면 Seq-ACK 정보를 이용하여 TCP Connection이 설립된다.


TCP client는 server에게 먼저 요청을 한다. 이 요청에는, 세그먼트를 보내는 데 헤더에 SYN 필드에 1을 담아 보낸다. 또한 헤더에 Seq # init number 또한 설정하여 보낸다. server가 정상적으로 recevied하게되면, SYN필드에 1을 담고, server의 Seq 번호를 설정하고, client의 seq 번호 +1 (cumulative 이므로)을 Ack으로 전달하게된다. ACK -> SYNACK이 수행되면, client는 SYNACK에 대해 한번 더 ACK을 하게 된다. 이는 client 입장에선 server로부터 SYNACK에 대한 ACK이므로, server입장에선 필요한 응답이다. SYNACK에 대한 ACK은 SYN 필드는 0 이며, data를 본격적으로 포함할 수 있다. data를 포함하던, 포함하지 않던, connection establish가 수행된다. 이를 3-way handshake 라고 부른다.

TCP 연결 종료를 위해서는 client가 먼저 FIN을 요청한다. 그 뒤 Server가 ACK을 송신하고, 그 뒤 Server는 자신이 보낼 segment를 다 보낸 뒤, server 또한 client에게 FIN을 송신한다. 그 뒤 client는 server의 FIN에 대해 ACK을 송신한다. 이 때, client는 바로 received buffer, sender buffer에 대해 메모리를 해제 하진 않는다. timed wait이라는 margin 시간 개념을 두고 천천히 메모리를 해제한다. 왜냐하면, 만약 client에서 보낸 ACK이 loss되면, server는 FIN에 대한 ACK을 받기위해 다시 FIN을 보낼 수 있기 때문이다. 그러면 client는 ACK을 재전송하기위해, 여전히 이전 메모리 정보들이 필요하기 떄문이다.
아래는 TCP에서 server와 client 서 발생하는 Connection Management의 절차를 도식화 한것이다.

TCP Principles of congestion control

TCP에서 처리 역량을 전제로, 전달하는 data 크기를 제어하는 방식으로 먼저 Flow control을 학습했었다. Flow control은 receive buffer 상황에 의해 결정된다. receive buffer는 Segment의 header에 담기므로 정량적으로 확실히 알 수 있다. congestion control은 Host와 Host간 사이에 있는 Network 상황에 의해 결정된다. congestion control은 Host간에 위치하는 무형의 Network를 측정해야하는데, 이는 공용 자원Public resource의 영역이다. 연결된 각각의 자원 resource들의 개별적 역량에 의해 결정된다.
만약 Network의 처리율이 낮아진 경우를 생각해보자. Host는 자신이 보낸 data에 대해 ACK을 유효한 시간내에 받지 못하였으므로 재전송을 하게 될것이다. 이 현상이 만약 계속하여 반복된 경우에는 Network에 계속하여 부하를 주게 된다. 결국엔 collapse가 발생하게 된다. TCP는 성공적으로 수행되기 위해서는, Network에 부하를 주지 않게끔 동작을 해야한다. TCP의 mechanism을 수행하기 위해선, Network 상황을 고려해야하고, 그 것을 성공적으로 하기위해 congestion control 개념이 발명된다. congestion control은 TCP라는 통신을 수립한 Host간의 (Peer-to-Peer의) reliable을 성공적으로 수행시키기 위해 이기적으로 전제되는 동작이지만, 결국에는 전체적인 환경인 Network를 파괴시키지 않는 쪽으로 기술이 발달된 과정이다. 반면에, UDP는 congestion control을 수행하지 않는다. Network에 의해 전송률이 늦어도 괘의치 않는다. 하지만 이 통신방법은 reliable을 보장하지않기에, 재전송 같이 Network에 부하가 되는 일은 하지 않으니 말이다. 반면에 TCP는 세심하게 공용 자원인 Network의 상황에 대해도 신경을 쓴다.

기술적인 이야기로 넘어와서, Network의 상황이 좋아지느냐 안좋아지느냐 의 판단 근거는 두 가지 방법에 의해 이루어 질 수 있다고 제시된다. 두 번째는 Network-assited 방법론이며, Network가 처리율 정보를 제공하는 방식이다. 각각의 router들이 queueing delay 따위들이 어떤 지 TCP를 수립한 두 HOST에게 정보를 제공하는 방식이다. 이는 이론적으로만 이야기된 것이고, 실제 Network 동작하는 방식이 아니다. 첫 번째는 End-to-End 방식인데, 이 것은 Network로부터 어떠한 정보를 받지 못하며 TCP를 수립한 두 Host가 Network 상황을 유추하여 congestion control을 수행하는 방식이다. 이는 현재 TCP가 congestion control로 채용하는 방식이다. sender는 delay나 loss에 따라 sender buffer의 windows size를 동적으로 변화시킨다. 이 것이, congestion control의 기본적인 원리이다.
TCP congestion control

TCP congestion control은 End-End 방식을 채용하고 있으므로, Network 상에서 어떤 router가 병목현상을 발생하는지 보고 받을 수 없다. 현재 TCP congestion control은 Host가 추정방식으로 결정하여 수행하고 있다.

첫 번째로, HOST는 겸손하게 Slow Start를 채용하고 있다. 처음엔 굉장히 작은 data를 전달하며, Network가 처리가능한 용량까지, 점차 전달하는 data크기를 늘린다.

slow start는 처음에 작은 크기를 전달하지만, 전달 data가 증가하는 크기는 exponential로 증가한다. (스크린샷 참고). 그래서 slow start보다 fast start라고 불러도 무관할만치로, 빠르게 증가한다. threshold에 도달하게 되면, linear하게 증가한다. (n배수) 이 때를 additve increase 이다. 어느 순간, packet loss를 감지하면, 절반으로 전송을 과감하게 줄이는데, 이를 Multiplicative decrease라고 한다. additive increase 절차에서 조심스럽게, linear 하게 n씩 늘리다가, Multiplicative decrease 절차에서는 과감하게 절반으로 줄인다. 이 이유는 Network에서 병목현상이 발생하였을 때, 각 각의 HOST 개체들이 조심스럽게 decrease하는 것보다, 과감하게 모든 Host가 확실히 크기를 줄여야 공용 자원에 대한 병목이 효과적으로 줄어들기 때문이다.

이 때, 전달되는 크기가 조절되는 원리는 windows size가 조절되는 것이다. 이 때, windows size가 조절되는 단위는 MSS(Maximum Segment Size)이다. 아래 그림은 linear 하게 증가하다 절반으로 줄어드는 전송 크기를 도식화 한 것이다.

전송속도가 제어되는 그림을 보면 마치 톱날 같아 Saw tooth behavior 라고도 불린다.

대략적으로 전송속도는 RTT(Round Trip Time, send후 ACK을 받는시간)로 Windows size를 나눈 것이다. RTT는 이전 포스트에서 보았듯이, 변화율이 있지만 (지수 평활법으로 추정한 것을 기억해보자), 일반적으로 좌항 rate는 Windows size의 변화가 더 크게 영향을 받는다. 일반적으로, windows size가 더 동적으로 변한다 는 의미이다.
아래는 congestion control에 대한 두가지 버전 1세대 Tahoe와 2세대 Reno에 대한 설명이다. Tahoe는 (하늘색 선) loss가 발생한 시점에 Threshold를 loss가 난 시점의 크기의 절반으로 설정하고 1 MSS로 slow start 절차부터 통신을 수행한다. 2세대 Reno는 Timeout일 경우 Tahoe와 같지만(timeout인 경우 packet loss이며, 일반적으로 Network 병목현상), 3 duplicated ack인 경우에서는 Network의 과부하로 보기 어려우므로, Threshold로 windows size를 설정하여 additive increase 절차부터 통신을 수행한다.

사족으로 Tahoe, Reno 알고리즘 이름은 카지노로 유명한 도시로 부터로 차용하였다. 그 다음 세대의 Congestion control 알고리즘의 이름 또한 카지노로 유명한 도시인 Vegas로 부터 차용한 Vegas 알고리즘이다.
TCP Fairness

TCP 세션들이 Network상황에 따라 send를 줄이도록 양보하는데, 각각의 session들이 다른 session들이 지나치게 임의의 session보다 지나치게 양보하는 상황이 발생하지 않을까? 라는 질문이 학계에서 유명했다고 한다. (마치 cpu 스케쥴링의 starvation같은 현상이 발생하지 않을까) 해당 동작을 직관적으로 판단하기 힘들었기에, 80년대에 이르러서 증명이 가능했다. 위의 그림은 router의 capa가 R이고 K TCP세션들이 있을 때, 정확히 R/K로 capa를 공평하게 쓰는지에 대한 질문이다. 아래 ppt는 각각의 TCP 세션들이 Fair하게 동작한다는 것을 보여준다.

임의의 session 두 개가 있을 때 하나의 session이 multicative decrease를 수행하여, windows size를 줄였고 그러한 현상이 계속 발생하다보면, 다른 세션에게 양보할 수 있는 capa가 점점 커질 것이다. 결국에는 공평하게 쓸 수 있도록 수렴할 것이다. 이에 대한 동작은 TCP 간의 공평함을 보여주는 것이라, 한 프로세스가 여러 TCP connection을 연 경우, 프로세스간의 불평등 사용을 초래하긴 할 것 이다.
중간고사 범위 끝이다.
내가 중간고사를 칠 순 없으므로, 다음 포스트에서는 해당 파트 까지 모든 내용을 정리한 Handbook 포스트를 해야겠다.....
'네트워크' 카테고리의 다른 글
| HTTP 정리 (0) | 2021.06.17 |
|---|---|
| 중간 과제) socket 프로그래밍 (0) | 2021.05.15 |
| 인강 ) 전송계층(2) - TCP (0) | 2021.05.04 |
| 인강 2) 애플리케이션 계층(완), 전송 계층(1) (0) | 2021.04.17 |
| 인강) 컴퓨터 네트워크 기본 2 (0) | 2021.04.10 |
- Total
- Today
- Yesterday
- 대규모 시스템 설계 기초
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- 시뮬레이션
- Simulation
- Discrete Mathematics
- 로젠
- beginning javascript
- 그라파나
- 명제논리
- 백준
- grafana cloud
- 아레나시뮬레이션
- 자바스크립트 예제
- 아레나
- 자바스크립트
- 데이터 중심 애플리케이션 설계
- 항해99
- 최단경로 알고리즘
- 엄청난 인내심과 시뮬레이션을 위한 아레나 툴
- Grafana
- flutter
- 이산 수학
- javascript
- Propositional and Predicate Logic
- 이산수학
- 아레나 시뮬레이션
- rosen
- paul wilton
- Arena
- arena simulation
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |