
티스토리 뷰
목차
- 문제 정의
- 트랜잭션 격리레벨
- SERIALIZABLE
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- 참고문헌
문제 정의
이 글은 Spring Boot 및 JPA기준으로 작성되어 있습니다.
send 함수의 수행 시간은 1회마다 1.x초 정도 소요된다. 목표치는 2600회 정도 이고 소요시간은 40분으로 측정된다.
안타깝게도, 해당 함수 호출을 하는 snedRegistered 함수가 여러 쓰레드에서 호출이 되었다. (sendRegistered 는 send함수를 여러회 호출한다. 목표치가 2600회이므로 2600번 호출된다.)
함수는 다음과 같이 작성되어있다.
@Transactional(propagation=Propagation.REQUIRES_NEW)
public void sendRegistered(Long scheduleId){
// 스케쥴된 아이템을 찾는다
Schedule sending = scheduleRepository.findById(alimtalkScheduleId).
orElseThrow(() -> new GeneralException(Type.NO_STORED_SCHEDULED_BY_ID));
List<ScheduledItem> items = sending.getItems();
boolean hasError = false;
// 해당 아이템의 하위 아이템들을 순회한다.
for (ScheduledItem item: items) {
// 해당 아이템이 수행되거나 끝났을 경우 넘긴다.
if (item.getBatchStatus().equals(BatchStatus.FINISHED) ||
item.getBatchStatus().equals(BatchStatus.RUNNING)) {
continue;
}
// RUNNING으로 마크한다.
scheduledItemService.markItemStatus(item.getId(), BatchStatus.RUNNING);
boolean curError = false;
try {
// A 함수를 하위 아이템에 수행한다.
curError = scheduledItemService.send(item);
} catch (Exception e) {
// 만약 에러가 있다면, 스케쥴된 아이템
hasError = curError = true;
scheduledItemService.markItemStatus(item.getId(), BatchStatus.FAILED);
} finally {
hasError |= curError;
if (!curError) {
scheduledItemService.markItemStatus(item.getId(), BatchStatus.FINISHED);
}
}
}
if (hasError) {
sending.setBatchStatus(BatchStatus.FAILED);
} else {
sending.setBatchStatus(BatchStatus.FINISHED);
}
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public boolean send(AlimtalkItem item){
// send함수의 메인 로직 1초 정도 소요된다.
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void markItemStatus(Long itemId, BatchStatus status){
// 아이템의 상태를 바꾸는 함수
ScheduledItem item = scheduledItemRepository.findById(itemId).orElseThrow(
() -> new GeneralException(Type.NO_STORED_SCHEDULED_BY_ID)
);
item.setBatchStatus(status);
}
복잡하지만, 함수 @Transaction(REQUIRES_NEW)를 사용한 이유는 예외가 발생하더라도 같은 트랜잭션으로 묶여서 상태가 롤백이 되지 않게끔 처리하려고 하였다.
트랜잭션간 모두 새로운 트랜잭션이므로, 다른 쓰레드간 동시성이 제대로 처리되는 걸까?
아마 독자분께서 프로그래밍을 어느정도 할줄안다면 위의 코드는 문제가 터질 것이 분명한 게 보일 것이다.
트랜잭션 격리레벨
우선 Transaction 에 대해 정리하고간다.
SERIALIZABLE
가장 단순하면서 엄격한 트랜잭션 격리 수준이다. SELECT 수행도 읽기 잠금을 획득해야한다. 동시에 다른 트랜잭션은 그 레코드에 대해서 작업을 할 수 없다. 즉, 한 트랜잭션에서 접근하고 있는 레코드를 다른트랜잭션은 절대 접근할 수 없으며 작업이 끝날때 까지 기다려야한다.
READ UNCOMMITTED
이 격리 수준에서는 트랜잭션간 커밋하지 않은 변경사항을 읽을 수 있다. 이는 트랜잭션에서 커밋하지 않은 변경한 사항을, 다른 트랜잭션 내에서 읽을 수 있다. Transaction 1에서 롤백이 되어 상태가 다시 READY로 변경되었다고 하더라도 여전히 트랜잭션 2에서는 RUNNING으로 판단한 로직이 진행될 수 있다. 물론 운이 좋게 적절한 시점에서 다시 바라본다면 READY일 것이다.

이처럼 어떤 트랜잭션에서 처리한 작업이 완료되지 않았는데도 다른 트랜잭션에서 볼 수 있는 현상을 더티 리드라고 한다. 더티 리드 현상은 데이터가 나타났다가 사라졌다가 하는 현상을 초래하므로 개발자와 사용자를 상당히 혼란스럽게 만들 것이며, 최소한 READ COMMITTED 이상의 격리 레벨을 쓰는 것을 권장한다.
하지만, 나쁜 도구는 없다고, READ UNCOMMITTED 가 속도가 중요하고 실패하여도 상관없는 작업이거나 멱등성을 보장하는 작업이면 READ UNCOMMITTED를 써도 무방하다. 자세히는 수행시 그 상태가 변경되고, 항상 그 상태가 고정될 때 동시성을 별도로 신경쓰지 않는다면 READ UNCOMMITTED가 유용할 수 있다. 또한 순수하게 READ 하는 작업, 즉 데이터 대시보드 등 오차가 있어도 되는 빠르게 읽는 작업들은 가능하다.
추가로, READ UNCOMMITED가 커밋하지 않는 변경값을 트랜잭션간 공유한다는 관점에서 레코드 Redis와 같지 않을 까 생각할 수 있지만, Redis는 싱글쓰레드를 지원하며 단 한 프로세스에서만 접근및 변경이 가능하며, 원자성을 띄며 일관성을 유지한다. 하지만, DBMS는 멀티 쓰레드이며 여러 트랜잭션에서 같은 레코드에 접근 및 변경할 수 있다. 따라서 일관성을 유지하려면 반드시 LOCK이 필요하다. 하지만 READ UNCOMMITTED 격리 수준은 LOCK이 반드시 필요하므로 순수히 READ UNCOMMITTED와 Redis의 동작은 다르다.
READ COMMITTED
READ COMMITTED는 오라클 DBMS의 기본 격리 수준이다. 한 트랜잭션에서 변경한 사항이 커밋되기 전까지는 다른 트랜잭션은은 언두 로그를 통해 읽는다. 커밋되지 않은 레코드는 다른 트랜잭션에서 변경된 값을 직접적으로 볼수가 없고 언두 영역에 백업된 레코드(=~언두로그)에서 가져온다. 최종적으로 커밋한 경우에 그 값을 볼 수 있다. 머메드로 도식화 하면 다음과 같다.
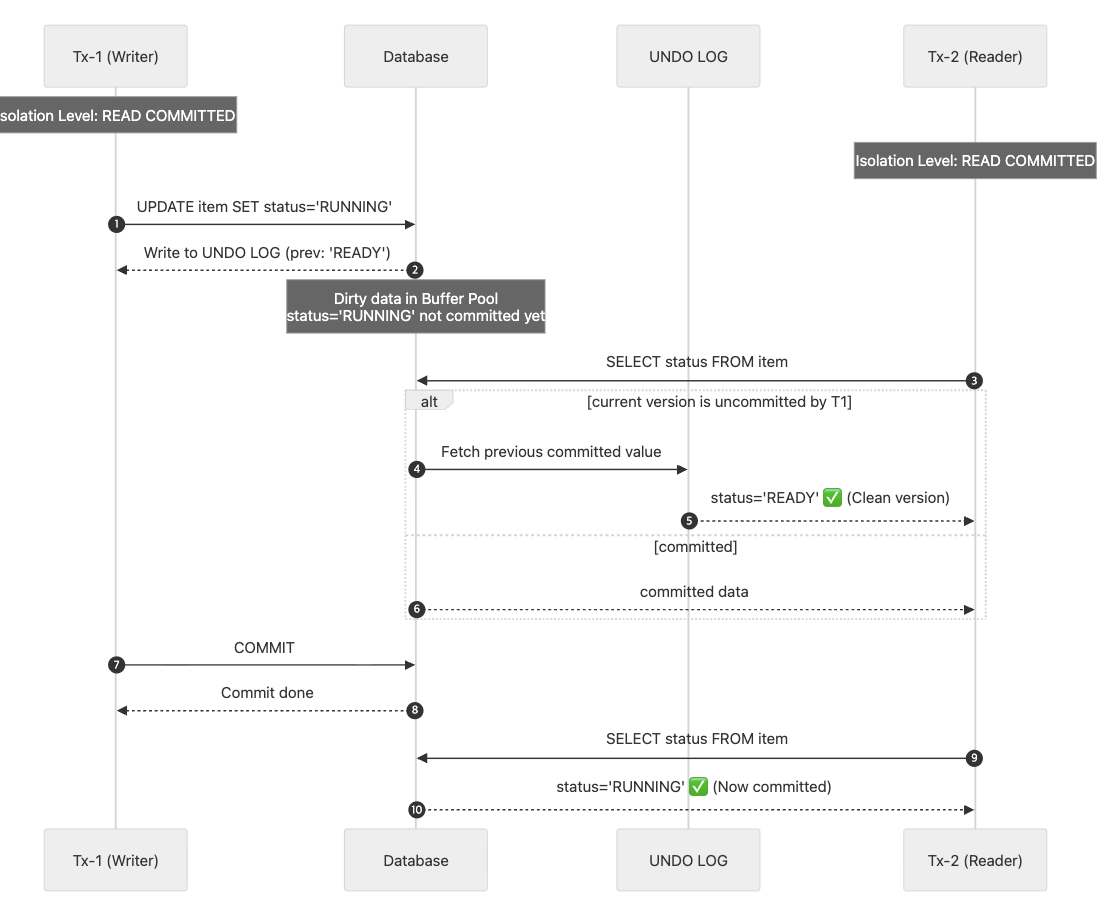
Tx-1 에서 기존값을 RADY -> RUNNING으로 상태를 변경할 시 UNDO LOG에는 기존 값 READY가 쓰여진다. Tx-2가 아이템을 읽을 때 이전 커밋된 값 READY를 읽어온다. 그리고 Tx-1이 커밋하게 된다면, Tx-2는 그 변경된 값을 읽게 된다.
위 설명에서 이미 눈치 채셨을 수도 있는 분도 있겠지만, 설명을 이어가자면 하나의 트랜잭션내에서 그 값을 반복적으로 읽을 수 없으므로 Non-Repeatable Read 라고 한다. Non-Repeatable Read 예는 다음과 같다. 한 트랜잭션에서 100으로 읽었을 때, 다른 트랜잭션에서 트랜잭션을 시작하여 값을 150으로 변경하고 커밋한 경우, 기존 트랜잭션에서 다시 그 값을 읽었을 때 150으로 읽을 수 있다. 머메드로 도식화 하면 아래와 같다.
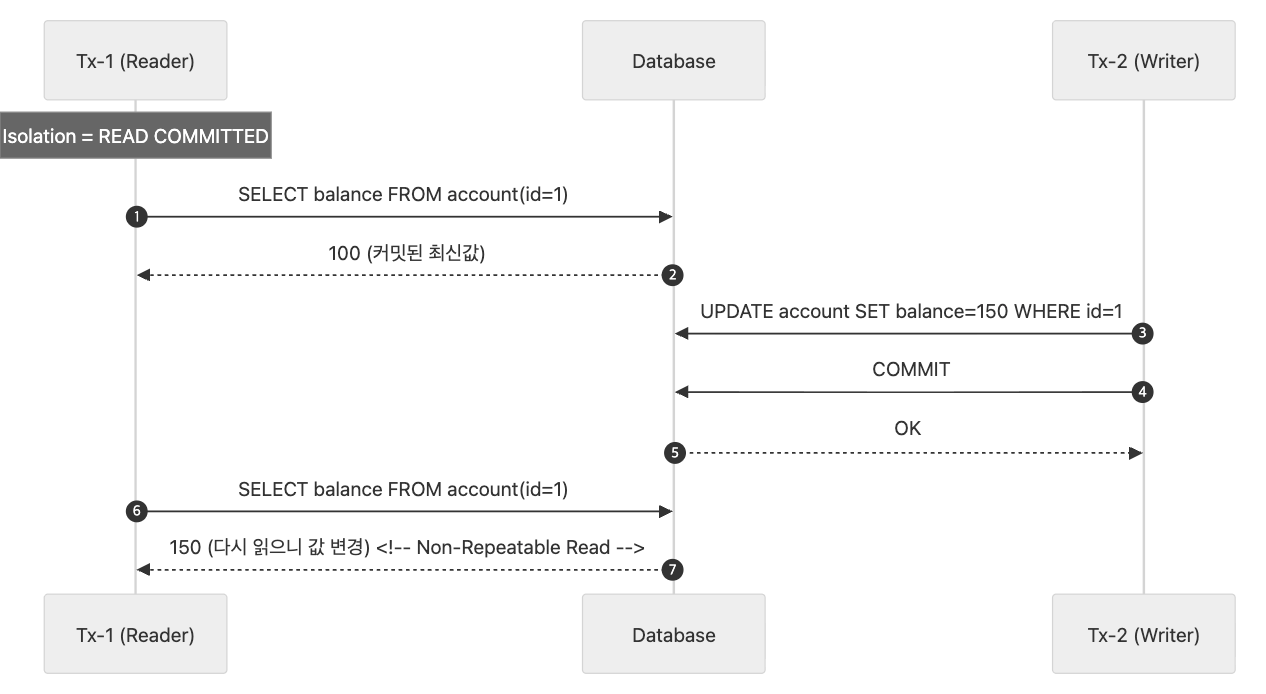
READ COMMITTED의 예 중 Non-Repeatable Read이다. 커밋하냐 안하냐를 떠나서 한 트랜잭션에서 접근하고 있는 레코드의 값이 갑자기 변경되어 다시 읽었을 때 그 값이 최초 읽은 값과 다른것이다. 이 것은 READ UNCOMMITTED와도 성격이 같다. 즉, READ UNCOMMITTED 또한 Non-Repeatable Read 성질을 가지고 있다.
한 트랜잭션내에서 여러번 값을 읽었을 때 동일한 레코드의 값이 바뀐다면, 크게 문제가 되지 않지만 금전적인 작업과 연결되면 문제가 될 수 있다. 예를 들어, 입금과 출금 처리가 계속 진행될 때 다른 트랜잭션에서 오늘 입금된 금액의 총합을 조회한다고 가정해보자. 그런데 총합을 계산하는 SELECT 쿼리는 실행될 때 마다 다른 결과를 가져올 것이다. 다른 결과를 가져와도 되지만, 중요한 것은 사용 중인 트랜잭션의 격리 수준에 의해 실행하는 SQL 문장이 어떤 결과를 가져오게되는지를 정확하게 예측할 수있어야 한다는 것이다.
REPEATABLE READ
독자 중에 트랜잭션이 열리지 않은 SELECT 와 트랜잭션이 열린 SELECT와 차이점이 무엇인지 궁금한 사람이 있을거다. 앞서 살펴본 READ COMMITTED, READ UNCOMMITTED 모두 다른 트랜잭션에서 SELECT한것과 트랜잭션없이 SELECT 한 것이 다를바가 없다. 맨처음 살펴본, READ UNCOMMITTED 는 트랜잭션을 열거나 없거나 SELECT 하는경우 다른 트랜잭션이 커밋하지 않은 변경한 값을 그대로 읽을 수 있다. 그리고 READ COMMITTED는 트랜잭션을 열거나 없거나 SELECT 하는 경우 다른 트랜잭션이 커밋한 변경한 값을 그대로 읽을 수 있다.
지금 살펴볼 REPEATABLE READ는, MySQL의 InnoDB 스토리지 엔진에서 기본으로 사용되는 격리 수준이다. 바이러니 로그를 가진 MySQL 서버에서는 최소 REPEATABLE READ 격리 수준 이상을 사용해야한다. InnoDB 스토리지 엔진은 트랜잭션이 ROLLBACK될 가능성에 대비해 변경되기 전 레코드를 언두 공간에 백업해두고 실제 레코드 값을 변경한다. 한 트랜잭션에서 수정하고 커밋한 내용이 있더라도, 다른 트랜잭션에서는 일관적으로 이전 커밋된 값만 읽어 오는 것이다. 다른 트랜잭션은 본인의 트랜잭션이 끝나기 전까지 이전 커밋된 값을 언두 로그에서 읽어온다. 따라서 본인의 트랜잭션이 끝났을 때 그제서야 다른 트랜잭션이 변경한 값을 볼 수 있다.
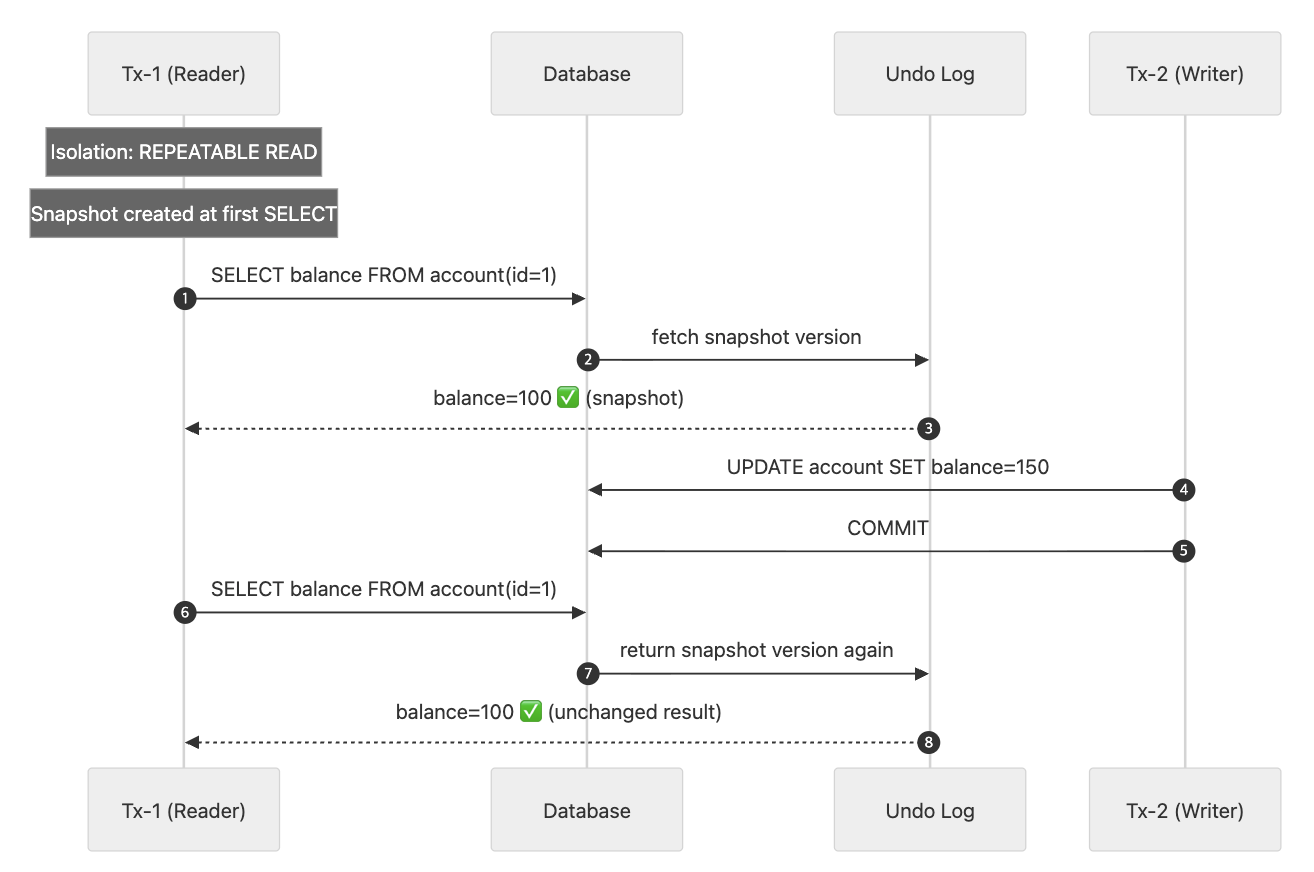
위 예는 Tx-1에서 트랜잭션을 열고, 계좌의 잔액이 100임을 확인한다. Tx-2가 트랜잭션을 열고 150으로 수정하고 커밋한다. 그리하여도 Tx-1이 다시 값을 읽을 때 언두 로그에서 본인의 바로 이전 데이터를 가져온다.
InnoDB 스토리지 엔진은 트랜잭션이 ROLLBACK 될 가능성에 대비해 변경되기 전 레코드를 언두 공간에 백업해두고 실제 레코드값을 변경한다. 이러한 변경 방식을 MVCC라고 한다. REPEATABLE READ는 이 MVCC를 위해 언두 영역에 백업된 이전 데이터를 이용해 동일 트랜잭션 내에서는 동일한 결과를 보여줄 수 있게 보장한다. READ COMMITTED도 MVCC를 이용해 COMMIT 되기전의 데이터를 보여준다. READ COMMITTED와 REPEATABLE READ의 차이는 언두 영역에 백업된 레코드의 여러 버전 가운데 몇 번 째 이전 버전까지 찾아 들어가느냐에 있다. READ COMMITTED는 바로 직전 커밋 버전 백업을 찾는다. 그래서 다른 트랜잭션에서 커밋이 일어나자마자 변경점을 언두로그에서 확인할 수 있다. 반면에 REPEATABLE READ는 트랜잭션을 시작할 때 바로 직전 커밋 버전 백업을 찾고 그것을 고정한다. 그래서 다른 트랜잭션에서 커밋이 일어나고 언두로그가 업데이트 되어도, 본인의 트랜잭션이 시작될때의 직전 커밋 버전 백업을 그대로 읽는다.
모든 InnoDB의 트랜잭션은 고유한 트랜잭션 번호(Increment)를 가지며, 언두 영역에 백업된 모든 레코드에는 변경을 발생시킨 트랜잭션의 번호가 포함되어있다. 그리고 언두 영역의 백업된 데이터는 InnoDB 스토리지 엔진이 불필요하다고 판단하는 시점에 주기적으로 삭제한다. REPEATABLE READ 격리 수준에서는 MVCC를 보장하기 위해 실행 중인 트랜잭션 가운데 가장 오래된 트랜잭션 번호보다 트랜잭션 번호가 앞선 언두 영역의 데이터는 삭제할 수 없다. 그렇다고 가장 오래된 트랜잭션 번호 이전의 트랜잭션에 의해 변경된 모든 언두 데이터가 필요한것은 아니다. 더 정확하게는 특정 트랜잭션 번호의 구간 내에서 백업된 언두 데이터가 보존되어야 한다. 유추할 수 있겟지만, 하나의 레코드에 여러 백업 버전이 존재한다. 만약, 트랜잭션이 길게 레코드를 잡고 있으면 그 언두 백업 로그는 무한정 커질 수도 있다. 그래서 MySQL 서버의 처리 성능이 떨어질 수 있다.
REPEATABLE READ에서도 특징적인 문제가 생길 수 있는데, 이 문제는 SERIALIZABLE을 제외한 모든 다른 격리 수준에서도 가지고 있다. 한 트랜잭션에서 레코드들을 스캔하였고, 대기중에 다른 트랜잭션이 데이터를 삽입하고 커밋하였을 경우, 삽입된 레코드는 본인의 트랜잭션이 끝나지 않아도 재 스캔시 발견이 되는것이다. 이를 PHANTOM READ라고 한다.
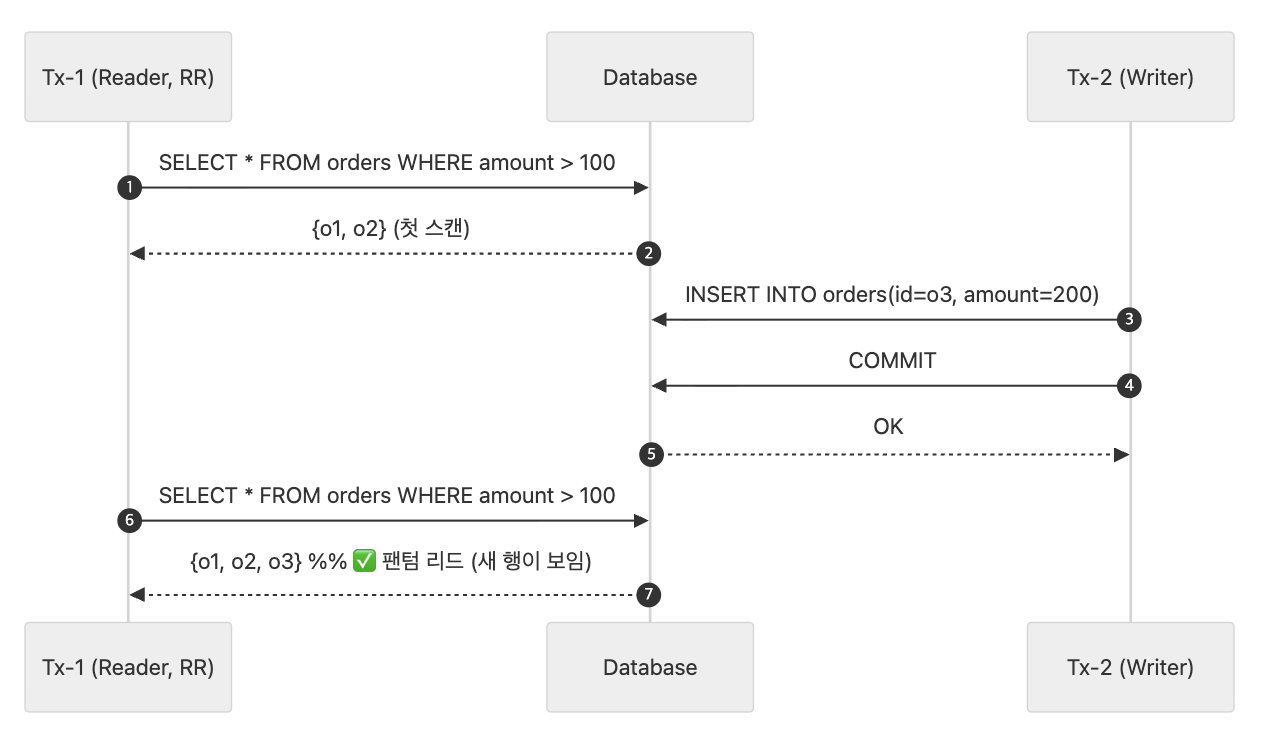
위 예에서 Tx-1 트랜잭션이 두번의 SELECT를 수행하는데 각각의 결과값이 다르다. 이처럼 다른 트랜잭션에의해 변경된 레코드가 보였다 안보였다 하는 것을 PHANTOM READ라고 한다. 레코드에 대한 락을 걸더라도, 삽입되는 레코드에 대해선 락을 걸수 없기 때문이다. 하지만 InnoDB에서는 갭 락과 넥스트 키 락 덕분에 REPEATABLE READ 격리 수준에서 이미 PHANTOM READ가 발생하진 않는다.
이 글에서는 문제 정의와 트랜잭션 격리 레벨에 대해 알아보았다.
다음 글에서는 동시성(비관적락, 낙관적락), 1차캐시에 대해 알아보겠다.
트랜잭션과 락은 레코드의 업데이트에 대해서 이야기 하기 때문에 긴밀하고, 그래서 헷갈리기 좋은 주제이다.
그럼 다음 글에서 보겠다!
참고문헌
- RealMySQL
'데이터베이스' 카테고리의 다른 글
| 트랜잭션과 동시성(락) (3) (0) | 2025.11.19 |
|---|---|
| 트랜잭션과 동시성(락)(2) (0) | 2025.11.11 |
| 인덱스 (0) | 2022.01.18 |
| 트랜잭션과 ACID 성질 (0) | 2022.01.16 |
| 인강 1) 관계 대수와 SQL (0) | 2021.06.29 |
- Total
- Today
- Yesterday
- 그라파나
- 엄청난 인내심과 시뮬레이션을 위한 아레나 툴
- 데이터 중심 애플리케이션 설계
- Propositional and Predicate Logic
- 최단경로 알고리즘
- rosen
- Arena
- 이산수학
- grafana cloud
- 아레나
- 자바스크립트
- 로젠
- 백준
- javascript
- 자바스크립트 예제
- 아레나시뮬레이션
- 동시성
- 아레나 시뮬레이션
- 이산 수학
- 대규모 시스템 설계 기초
- 명제논리
- paul wilton
- arena simulation
- 시뮬레이션
- Discrete Mathematics
- 항해99
- beginning javascript
- 트랜잭션
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- Simulation
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |