
티스토리 뷰
Binary Search Tree, 이진 검색 트리
gaelim 2018. 10. 25. 15:47/*
The source of this article is from
1 Wikipedia (https://en.wikipedia.org/wiki/Binary_search_tree)
2 Geeks for Geeks (https://www.geeksforgeeks.org/binary-search-tree-set-1-search-and-insertion/)
3 Introduction to algorithm 3rd edition
4 Handbook of discrete and combinatorial mathematics.
I just write down this post for my learning in CS.
I don't have any authority for comercial uses with this article, and with any part of this article.
*/
이진 검색 트리 Binary Search Tree
Introduction
검색 트리 자료 구조는 많은 동적 연산을 지원한다, SEARCH, MINIMUM, PREDECESSOR, SUCCESSOR, INSERT, 그리고 DELETE. 따라서 우리는 검색 트리를 사전 또는 우선 순위 큐 처럼 사용할 수도 있다. (SEARCH, MINIMUM)
이진 검색 트리에 대한 기본 연산은 트리의 높이에 비례한 시간을 소비한다. n개의 node가 있는 complete binary tree는, 높이가 log n 이므로 최악의 케이스 시간으로 O(lg n) 에 동작한다. 만약 binary tree의 n 개의 노드가 선형으로 사슬처럼 연결되어 있다면, 높이가 n 이므로, 이전과 같은 연산이 최악의 케이스 시간으로 O(n) 에 동작한다. 분명한 것은, 무작위로 지어진 binary tree의 예상 수행 시간은 O(lg n) 복잡도를 가진다는 점이다. 그래서 평균적으로 수행복잡도가 O(lg n)을 가진다고 한다.
구현에선, 이진 검색 트리가 랜덤하게 빌드된다고 항상 보장할 수는 없지만, 기본 수행에 대해 잘 검증된 최악의 케이스 수행 시간을 가지는 다양한 이전 검색 트리를 설계할 수는 있다. 이 종류에는 AVL tree, Red-Black tree, B-tree 등이 있다. (조금은 어렵겠지만... 추후 포스트에서 자세히 다룰 것이다.)
이번 주제에서는 순전히 기초적인 Binary Search Trees 에 대해 살펴볼 것이다.
이진 검색 트리 Binary Search tree란?
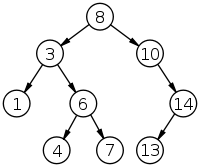
<key가 정수인 이진 검색 트리, 위키피디아>
각 노드는 정확히 좌, 우 자식 노드를 한 개 이하로 가지고 있다. 그렇다면 key와 child, parent property는 무슨 관련이 있을까?
Introduction에서 서술했듯이, 우리가 이 이진 검색 트리를 이용해 SEARCH 작업을 평균적인 최악 수행 시간 O(lg n) 시간에 할 수 있다는 것을 기억하자. 무언가가 있으니까 선형 탐색 O (n) 보다는 작은 것 아닐까? ㅋㅋ.
바로 binary-search-tree의 핵심적 속성은 그 노드의 key와 child, parent의 결정에 있다.
"x를 이진 검색 트리의 노드라고 하자. 만약 y가 x의 왼쪽 subtree에 있다면, y.key <= x.key 이다. 만약 y가 x의 오른쪽 subtree에 있다면, y.key >= x.key를 만족한다."
다시 이 포스팅에 삽입되어 있는 위 그림(위키피디아 출처)을 살펴보면, 정확히 이진 검색 트리의 속성을 따르고 있는 것을 확인할 수 있다.
실제로, 앞으로 tree를 이용해 어떤 자료구조를 만들고 효율적인 작업을 수행하려할 때 그 tree를 빌드할 때 key와 child, parent property의 연관성이 주 요소일 것 이다. 내가 포스팅 했던 자료중에 heap과 관련된 포스팅이 있다. 잠깐 짚고 넘어가자면 heap은 실제로, 개념적으로 tree를 구성하는 것이며 min, max 성질 중 하나를 가질 수 있다. 이 때 max heap은 속성은 다음과 같다.
ParentNodeOfNode.key >= Node.key
따라서, Max-Heap tree에서는 tree의 root node가 가장 크며, 이 것은 key값에 대해 정렬을 하는데 큰 힌트가 된다. 만약 heap tree에 관심이 있다면 (여기를 클릭)
이진 검색 트리에 대한 Operations set
1 traverse on binary search tree
이진 검색 트리가 만들어 져있다고 생각해보자. 검색 트리의 요소인, node는 in-order 방식으로 찾을 수 있다.

<In-order 는 LNR이라고도 불리며, Left subtree - Node - Right subtree로 재귀적으로 순회한다.>
코드는 다음과 같다.

위 알파벳 키를 가진 트리에 대해 in-order traverse 함수를 수행하면, 출력물은 다음과 같다.
A B C D E F G H I
순회는 정확히 n개의 노드를 모두 순회하기 때문에 O (n) 수행 복잡도를 가진다.
2 Searching
2.1 Searching a specific key

이 search 방법은 node를 만날 수 있을 만큼 수행 한다. 다만, 모든 node가 아닌 한 node에서 반복적으로 왼쪽 또는 오른쪽으로 결정된 walk에서 만날 수 있는 node이며 최악의 수행시간은 tree의 높이만큼인 O(h) 이다.
2.2 Searching a MIN, MAX key

2.3 Searching a Successor, Predecessor
binary search tree에서의 Successor는 다음과 같이 정의된다.
"x의 Successor는 x.key 보다 key 값이 크며, 그 node 들 중 가장 작은 key 값을 가진 node를 말한다."
binary search에서 lower bound와 비슷한 것이다.
successor와 predecessor를 찾는 것에는 binary search tree node의 키가 distinct하다고 가정한다.
여기서 흥미로운 점은, key값을 비교하여 탐색하지 않고 단순히 binary search tree의 구조를 활용하여 Successor를 찾을 수 있다는 것이다. 참 아름답다고 생각한다. ( -_- ... 나만 그렇게 느꼈나 )
x의 Successor를 찾는 것에는 두 가지 경우의 수가 있다.
첫 번째는 만약 노드 x의 우측 subtree가 존재할 경우, 해당 우측 subtree의 min(SubtreeRoot)을 수행하면된다.

x보다 크면서 가장 작은 node는 우선 x의 우측 subtree의 가장 좌측 subtree 말단 node인 것은 자명하다. 하지만 만약 x의 우측 subtree가 존재하지 않는다면? x가 어떤 점 y의 left subtree일 수 있다는 것을 고려해보자. x가 y의 left subtree의 한 점이라면, 이진 검색 트리의 정의에 따라 y의 key는 x key보다 크다. 결국, x에서 출발하여 위로 거슬러 올라가며 가장 먼저 만나는 x를 left subtree로 가지는 node를 찾으면된다. 그림은 다음과 같다.

만약, x가 right subtree를 가지면서 또한 x 자신을 left subtree로 가지는 노드를 가지고 있으면 y = min(x.RightSubtree) 와 z = MyFirstRightParent(x) 중 어떤 것이 x의 successor 일까?
x의 Right subtree의 임의의 원소를 y라고 하자. 그리고 z를 x를 left subtree로 가지는 x와 가장 가까운 부모 노드라고 하자. 그렇다면 z는 x와 x.RightSubtree 를 Left Subtree로 가진다. 따라서, x.key< y.key < z.key (assumes keys are distinct) 이다. 따라서 min(x.RightSubtree)가 x의 Successor 이다.
코드는 다음과 같다.

자기 자신을 왼쪽 subtree로 가지는 가장 가까운 부모 노드를 찾는 것은 자기 자신을 또는 자기 부모를 참조하는데 오른쪽 자식으로 참조하는지 반복적으로 검사하면된다. 만약 그러한 부모가 없다면, y는 null (0) 을 가지게 될것이다. 이렇게 갔다는 것은 x (now) 노드 부터 tree root 까지 좌상향 했고 tree root의 부모는 존재하지 않으니 y가 0으로 갔다는 것이다.
3 Insertion
삽입은 트리 순회나 특정 키 검색과는 다르게 트리에 노드를 추가함으로써 트리를 변경하는 작업이다. 삽입한 후에도 이진 검색 트리의 속성을 유지해야한다.
삽입은 다음을 지키며 수행하면 된다. 우선은 지시자를 root node에 놓고 시작한다. 만약 root node의 key보다 삽입할 node의 key 값이 작으면 왼쪽 subtree로 이동하고, 삽입할 node의 key 값이 크거나 같을 경우 오른쪽 subtree로 이동한다. 그리고 이 것을 반복하되, 현재 node 지시자가 가르키고 있는 node가 없으면 그 때 새 node를 그 지시자가 있는 자리에 삽입한다.

4 Deletion
deletion 은 transParent 라는 함수를 정의해서 사용하려고한다.
transParent는 A 노드의 자리로 B 노드를 이동할 때 A 노드의 부모의 정보를 A로 가지고 있는걸 B로 갱신시켜 주는 것이다. 그리고 B의 부모를 A의 부모로 갱신시켜 준다.


전체 코드 보기
이진트리를 처음 작성해보는 건데, deletion 파트에서 책 예제와 인터넷 예제가 많이 달라서 당황했다. 특히 책에서는 노드를 완전히 참조 가능한 어떤 것으로 다루고 있었는데 인터넷에서는 key value 기준으로 tree를 탐색한후 같은 key 값을 가진 노드를 제거하는 것이였다. 내 예제에서는 del 함수에서 del 노드를 (젠장 이제보니 함수랑 지역변수랑 이름이 똑같네) 완전히 어떤 참조가능한 개체로 작성되어있다. 만약 key value기준으로 탐색해야한다면 searchWIthVal 함수를 적극 활용해야할것이다.
아래 깃헙에서는 Key value 기준의 사용에 대해서 적용해놨다.
만약 Node 를 하나의 개체로 보고 사용하려면 main에서 또 다른 저장소 Node* arr [ ] 이용해서 쓸수도 있을 듯 하다.
https://github.com/ingyeoking13/algorithm/blob/master/algorithm/tree/binary_search_tree.cc
정리하기
백준 문제풀어보기 -백준 5639 이진 검색 트리
'Discrete mathmatics and Problem Solving > 11 트리' 카테고리의 다른 글
| Segment Tree with Lazy Propagation (0) | 2019.03.10 |
|---|---|
| AVL tree (0) | 2018.10.28 |
| B+ trees (0) | 2018.10.27 |
| 이진 힙과 힙정렬 binary heap && heap sort (0) | 2018.02.06 |
| 트라이 자료구조Trie datastruct (2) | 2018.01.12 |
- Total
- Today
- Yesterday
- Discrete Mathematics
- Propositional and Predicate Logic
- 이산수학
- javascript
- Simulation
- 시뮬레이션
- 명제논리
- arena simulation
- Grafana
- 항해99
- 아레나 시뮬레이션
- Arena
- 자바스크립트 예제
- rosen
- 아레나
- 아레나시뮬레이션
- 그라파나
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- 백준
- 자바스크립트
- 데이터 중심 애플리케이션 설계
- 로젠
- 엄청난 인내심과 시뮬레이션을 위한 아레나 툴
- grafana cloud
- beginning javascript
- 최단경로 알고리즘
- 대규모 시스템 설계 기초
- flutter
- paul wilton
- 이산 수학
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |