
티스토리 뷰
http://www.kocw.net/home/cview.do?cid=d549f8570583094b
https://www.youtube.com/watch?v=NkZ6r6z2pBg&ab_channel=%EC%9A%B0%EC%95%84%ED%95%9CTech
https://www.youtube.com/watch?v=9ZXIoh9PtwY&ab_channel=%EC%9A%B0%EC%95%84%ED%95%9CTech
https://www.youtube.com/watch?v=P5SZaTQnVCA&ab_channel=%EC%9A%B0%EC%95%84%ED%95%9CTech
http://ko.infomngproeng.wikidok.net/wp-d/60a1e50990b350fb11df6fa4/View#wk_cTitle4210
https://ssup2.github.io/theory_analysis/B_Tree_B+_Tree/
https://infocenter.sybase.com/help/index.jsp?topic=/com.sybase.dc20021_1251/html/locking/
https://mozi.tistory.com/319
인덱스와 Full Scan
인덱스는 데이터를 빠르게 추출/삭제하기 위한 도구이다. 만약 단순히 데이터가 List로 되어있다면, Full Scan을 수행하여 O(n)의 시간복잡도를 가질 것 이다. 만약 List로 되어있지만 정렬이 되었다면 이진탐색으로 시간복잡도 O(log_n)으로 가능할 것 이다. 인덱스는 이진탐색과 시간복잡도가 유사하다. 인덱스는 B+ Tree 자료구조를 활용한다.
Binary Tree, B Tree, B+ Tree
세 트리 모두 조회에서 log_n의 평균 복잡도를 가진다. Binary Tree는 그 자체로 Balanced를 뜻하지 않으므로 Biased할 수 있다. 종종 AVL, Red Black Tree, Heap Tree 등을 Balanced Tree를 만드는 방법으로 제시되었다.

반면 B Tree, B+Tree는 그 자체로 Balanced하며, n-ary Tree 이다. B- Tree 와 B+ Tree의 차이점은, B- Tree는 모든 노드들 마다 본인의 key-value를 가지고 있지만 B+ Tree는 리프 노드만 key-value를 가지고 있고 그 외의 노드는 기준을 위한 key만 가지고 있다.

아래의 그림에서 보이다시피 B+ Tree는 리프노드에만 데이터가 있다. 그리고 리프노드간 연결되어있다.

Primary Key, Clustered Index
테이블에 Primary Key를 생성하는 경우 기본적으로 Clustered Index를 생성한다. Clustered Index는 가장 좋은 성능을 발휘하고, 테이블에 한개밖에 생성할 수 없기 때문에 주로 Primary Key를 기준으로 잡는 경우가 많다. Primary Key를 Non-Clustered Index로 설정할 수 있으나 그렇게 잘 쓰지 않는다는 의미이다. 즉, 카디널리티가 높은 것이 Primary Key로 정하는 것이 좋다.
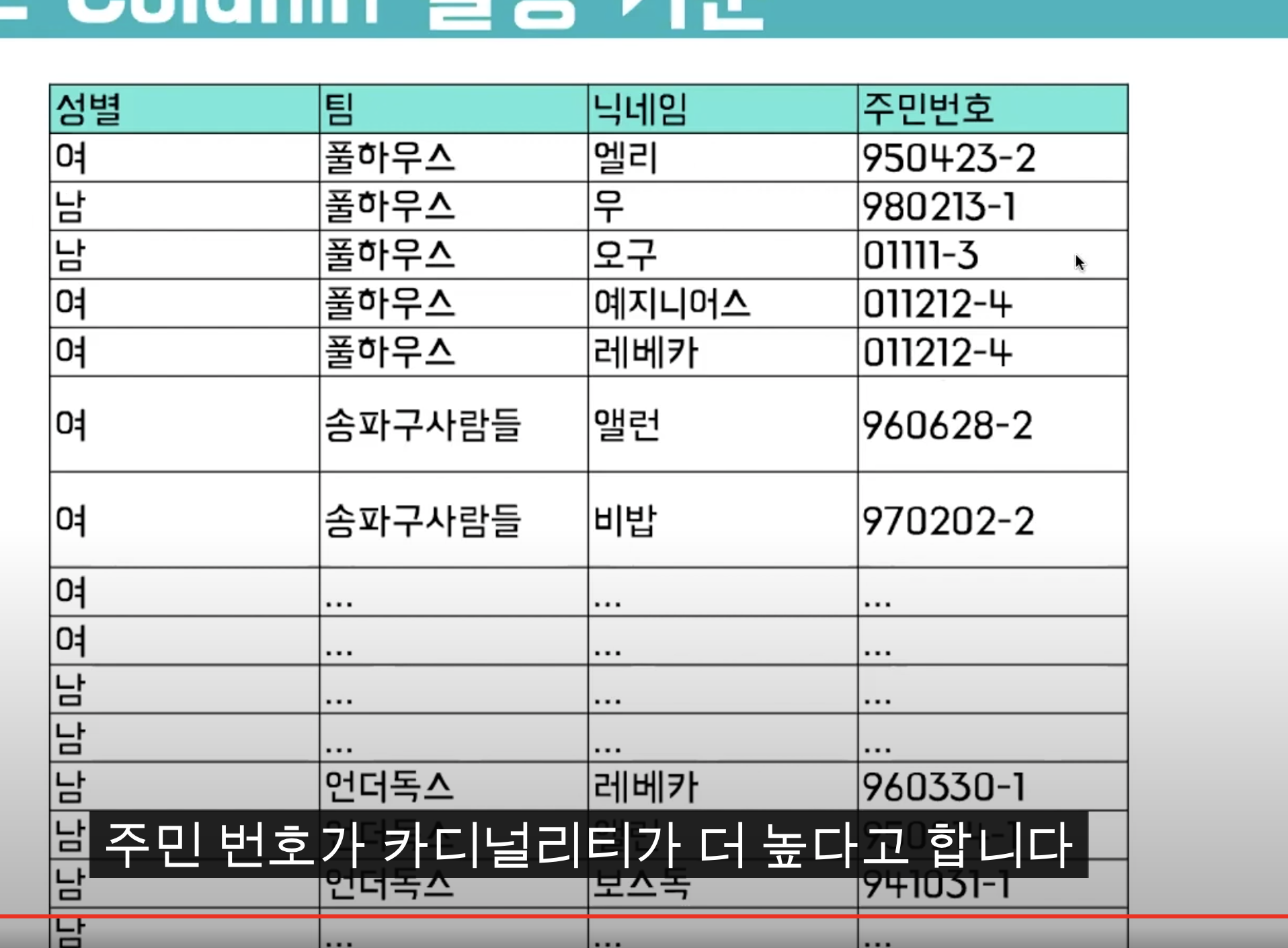
또한, 값의 크고 작음의 변곡이 큰 Primary key보다 순서대로 증가하는 크기가 더 좋다. 후자의 경우에 INSERT시 작업이 덜 든다. INSERT 작업에 관한 것은 곧 설명이 나온다.

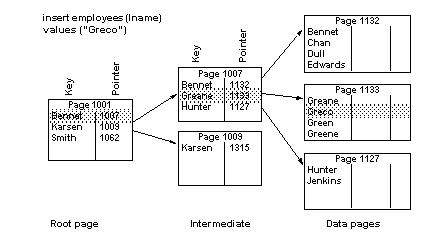
실제로 Key-Pointer 형식으로 구현되어 있으며, 포인터는 브랜치 노드 또는 리프 노드의 페이지 주소를 가르킨다. 아래는 데이터 삽입을 수행하면서 페이지가 늘어나는 양상을 보여준다.
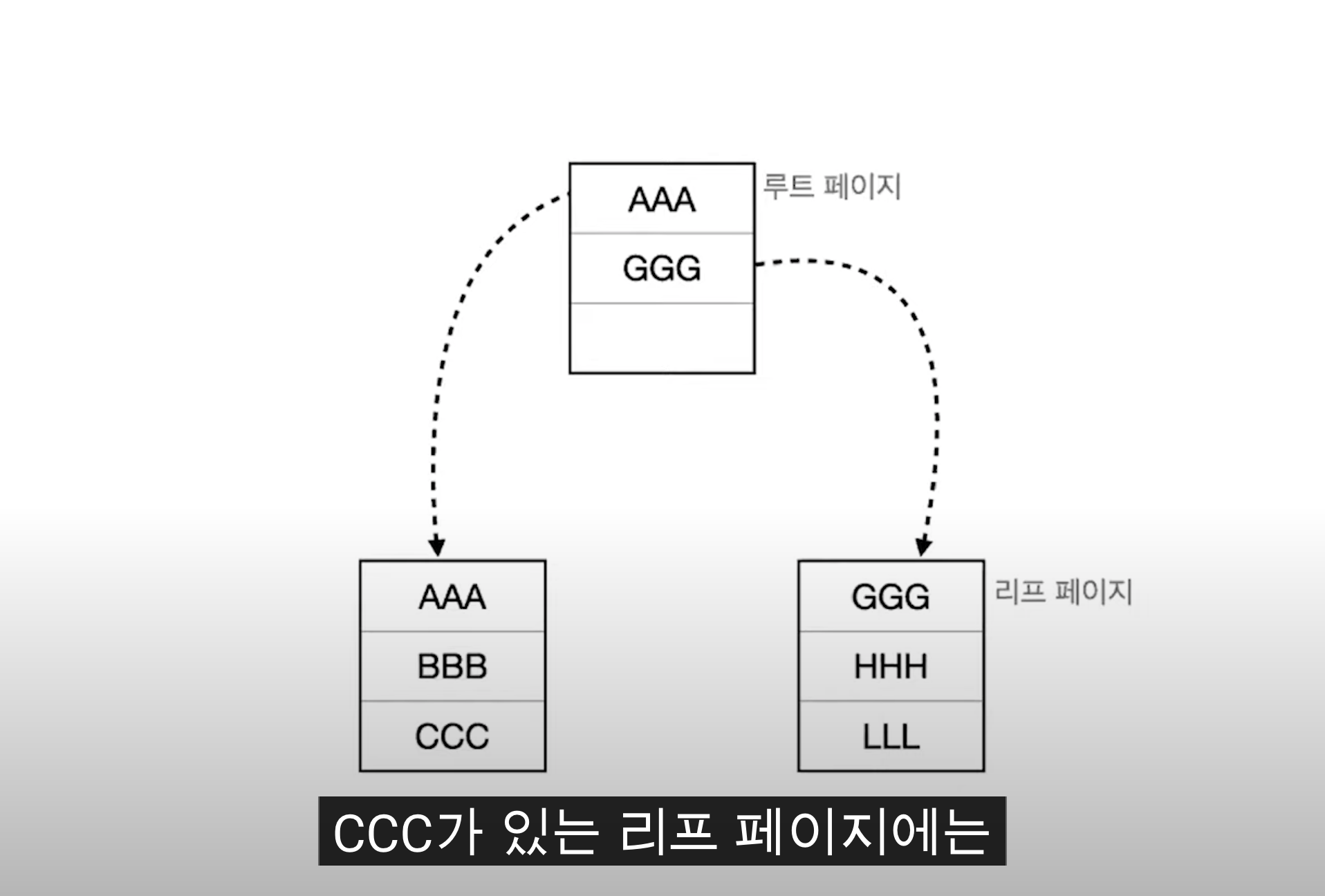
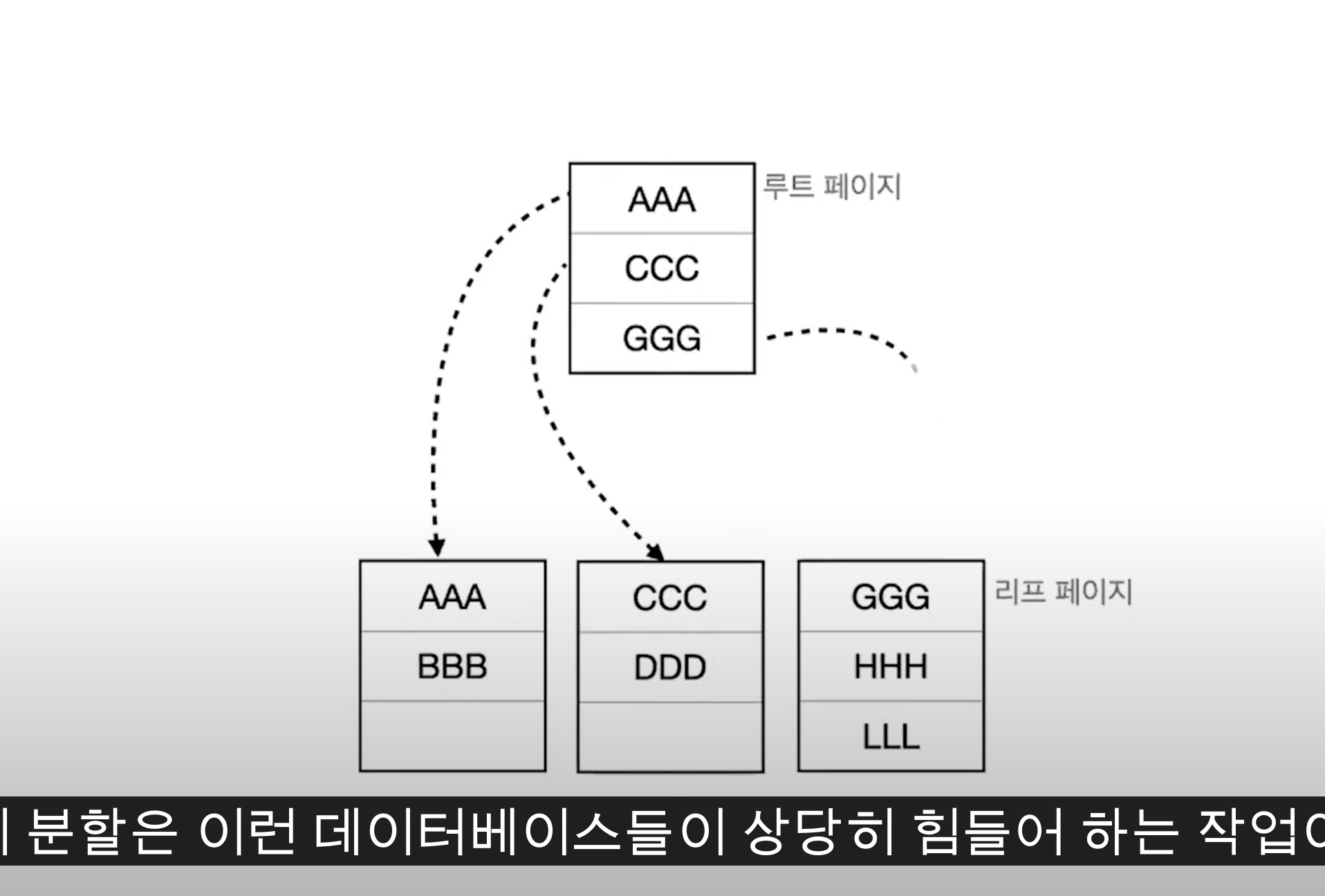
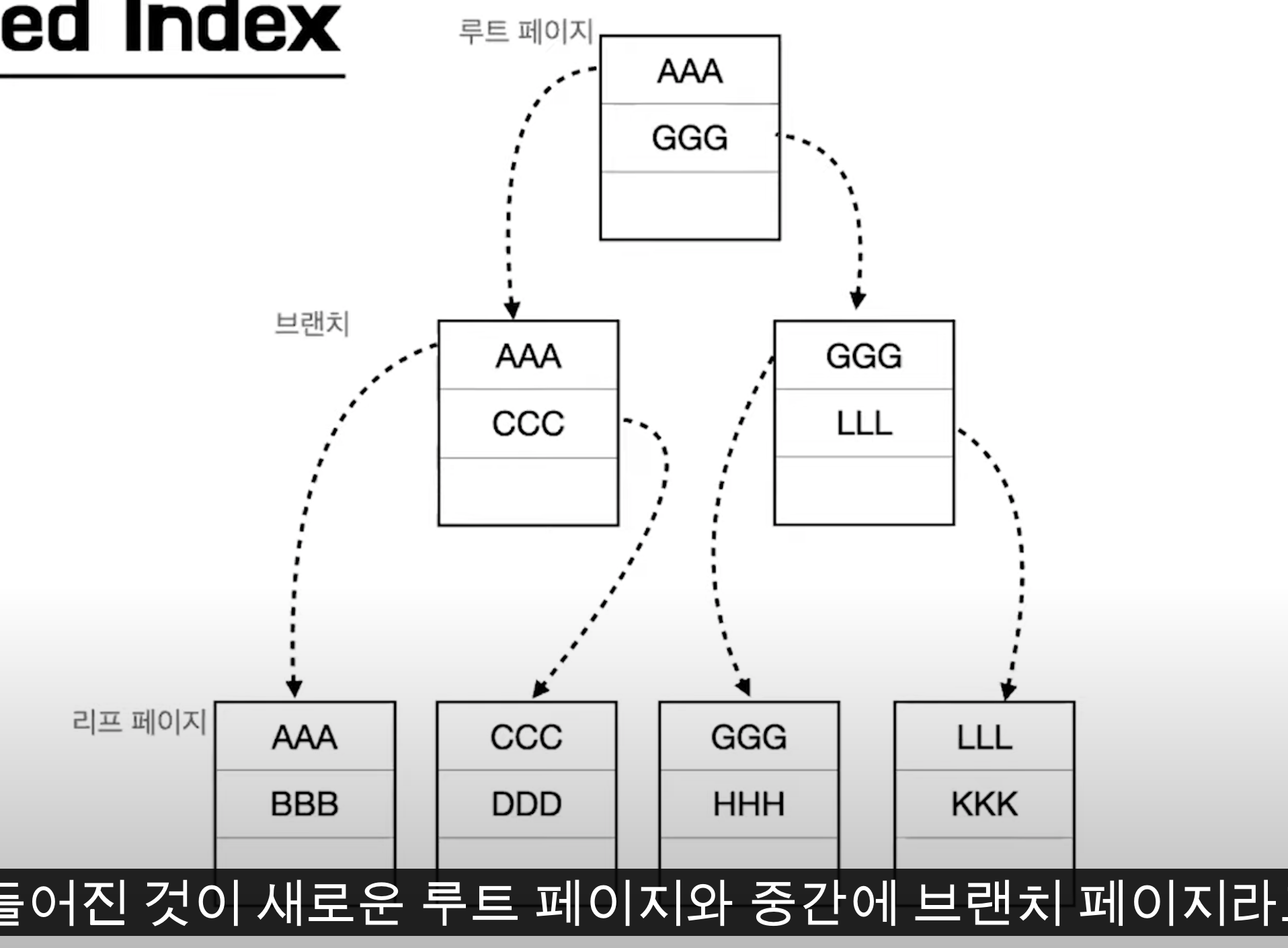
브랜치 노드가 늘어나는 양상을 보았을 때, INSERT DELETE 작업은 Index를 생성하였을 때 손해를 보는 부분이다. 그리고 중간에 삽입할 때 브랜치, 리프 페이지 노드가 많이 변할 것이란 걸 유추가능한다.

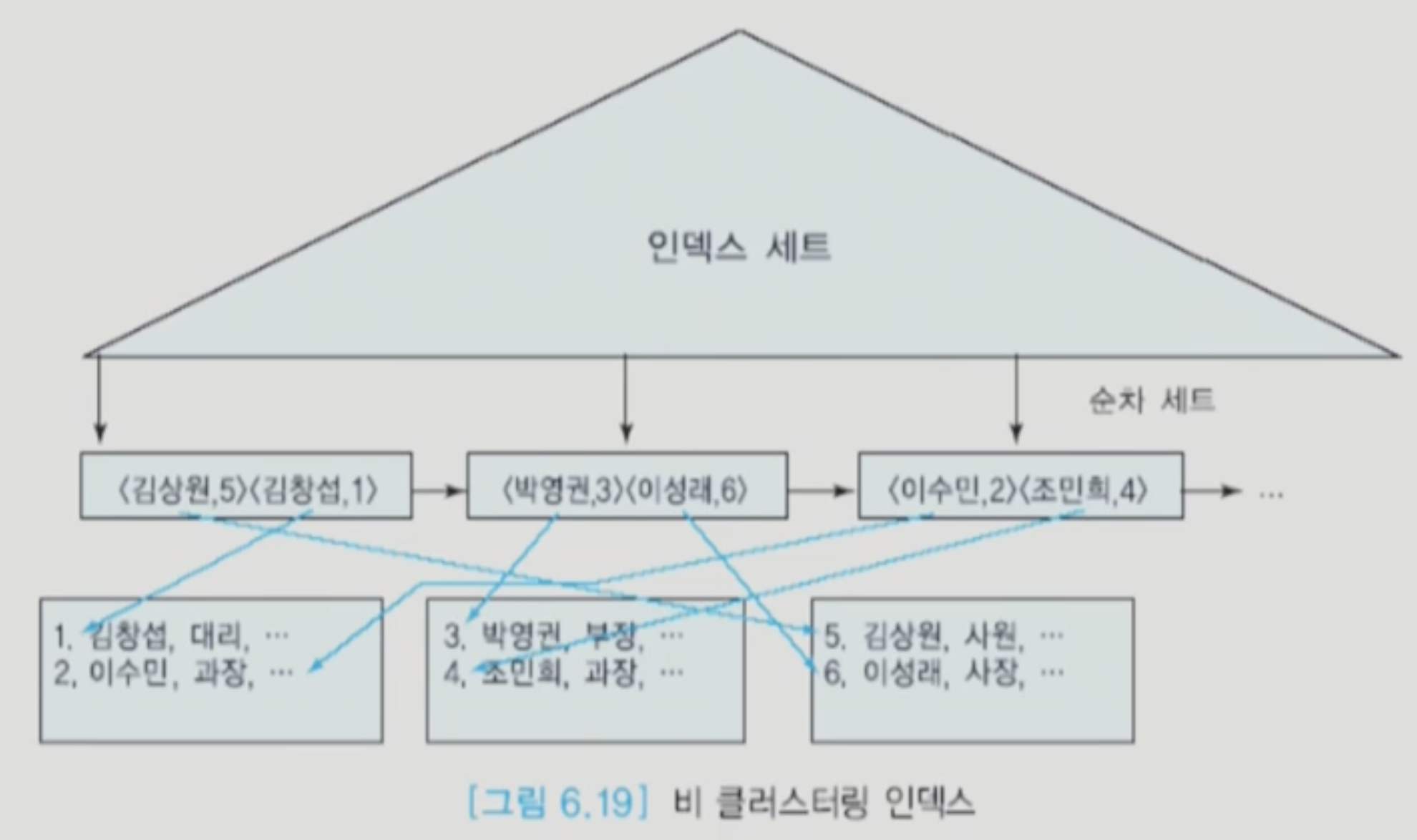
Non Clustered Index
보조 인덱스라고 한다. 테이블에 여러 개가 존재할 수 있다. 데이터파일과 인덱스 페이지의 순서가 다르다는 특징이 있다. 그래서 Range Query를 처리하려면 리프노드상 순서대로 연결되어있는 것이 순서대로 되어있지 않기 때문에, 인덱스 엔트리를 따라 하나하나씩 수집해야한다. (반면 클러스터링 인덱스는 리프노드간 정렬이 되어있고 순서대로 연결이 되어있어 구간 검색이 빠르다.) Unique 제약조건으로 컬럼을 생성할 수 있다. 그리고 Clustered Index 와 비교해서 조회는 느리지만, Insert 등의 변경 작업은 보다 빠르다.


'데이터베이스' 카테고리의 다른 글
| 트랜잭션과 ACID 성질 (0) | 2022.01.16 |
|---|---|
| 인강 1) 관계 대수와 SQL (0) | 2021.06.29 |
- Total
- Today
- Yesterday
- 아레나
- Trie
- Discrete Mathematics
- 엄청난 인내심과 시뮬레이션을 위한 아레나 툴
- 명제논리
- Simulation
- 백준
- arena simulation
- 최단경로 알고리즘
- 이산 수학
- 조합 코딩
- 시뮬레이션
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- flutter
- 로젠
- 데이터 중심 애플리케이션 설계
- Propositional and Predicate Logic
- 그라파나
- paul wilton
- 대규모 시스템 설계 기초
- 아레나시뮬레이션
- beginning javascript
- 자바스크립트 예제
- rosen
- 아레나 시뮬레이션
- 이산수학
- javascript
- grafana cloud
- 자바스크립트
- Arena
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |