
티스토리 뷰
강의 url) www.kocw.or.kr/home/cview.do?mty=p&kemId=1169634
1) 인터넷을 동작시키는 컴퓨터네트워크 프로토콜을 학습한다.
2) Multiplexing/Demultiplexing와 Error detection을 이해한다
3) UDP와 TCP의 특징을 이해하고, TCP의 RDT를 이해한다.
4) RTT의 문제를 개선하는 방법에 대해 알아본다.
What is socket?
- 어플리케이션 프로세스 들 끼리의 통신이므로, 결국엔 Client - Server 간의 통신이다. 결국엔 App이라, Application 사용자나 개발자 입장에서는 OS 내부의 구현을 건드릴 필요도 알 필요도 없다. 그러나 전문가의 입장에선 OS 내부로 들어가야 한다.
- 개발자 입장에서는 OS가 제공하는 서비스/인터페이스를 사용하면 된다. 프로세스 간 통신을 하기 위해선 경우 OS가 제공하는 인터페이스 Socket이다.
- Application Process는 Socket을 사용하되, 해당 Layer 밑에 있는 Transport Layer가 제공해주는 서비스를 이용해야한다. 현재 OS Transport Layer가 제공하는 TCP 또는 UDP라는 프로토콜을 사용해야한다. 따라서 Application은 TCP socket을 사용하거나 UDP socket을 사용할 수 있다. TCP socket에 write 하면 TCP로 전송, UDP socket에 write 하면 UDP로 전송한다.
Socekt API
Socket Functions TCP Case
TCP server : socket() - bind() - listen() - accept()
1) TCP socket을 열고, (특정 parameter를 전달한다.)
2) 해당 socket을 특정 port에 bind한다.
3) 해당 socket을 listen 용도로 쓰겠다고 함.
4) client를 받아들일 준비를 하여 기다림. process blocked. client로 부터 connection 이 들어올때까지 blocked. (내 생각: socket 하드웨어로부터 인터럽트가 들어올때까지 기다리는 것인가?)
TCP client : socket() - connect()
1) TCP socket을 열고
2) 서버의 프로세스에게 connect를 요청한다. TCP three-way handshaking이 끝나면 TCP socket 둘 사이에 단단한 연결고리가 형성된다.
추후엔 read() write()를 연속적으로 수행하며 close()를 하여 끝나게된다.

클라이언트에서 호출되는 connect 함수에서는 연결될 상대 서버의 IP와 port가 인자로 넘어갈 것 이다. 그런데 클라이언트에서 bind()함수는 호출하지 않는 이유는 무엇일까? 강의 14:35 ~ ) bind() 함수는 socket을 특정 port에 연결시키는 함수인데, 클라이언트는 socket이 어떤 port에서도 write하여도 되기 때문이다. 서버의 경우 socket이 웹서버인 경우 80으로 써야한다. 클라이언트에서도 socket을 특정 port로 bind하고 써도 되긴한다.
Project 1: Web server
- 웹 서버를 c로 구현해본다.
- 1. HTTP Request를 받아 그대로 terminal에 출력해본다.
- 2. HTTP Request를 parsing하여 지정 file을 client에 제공해준다.
Transport Layer
multiplexing and demultiplexing
앱 계층의 프로세스가 네트워크를 쓸 때, Transport Layer로 내려보낼 때 segment화 하는 것을 multiplexing이라 하며, demultiplexing은 그와 반대로 Transport Layer밑의 Physical Layer - Link Layer - Network Layer로 통해 Transport Layer로 segment를 분해하여 App 계층으로 전달할 때 사용된다. multiplexing은 여러 socket을 통해 들어오는 자료를 segment로 만들어 내려보내고, demultiplexing은 하나의 segment를 분석하여 여러개의 socket 중 하나로 전달한다. multiplexing은 sender transport 측에서, demultiplexing은 receiver transport 측에서 발생한다. segment란 header + data로 이루어진 32bit 자료구조이다. Transport Layer에서 Segment 자료구조를 만드는데 header와 body로 이루어져있다. header에는 여러 부가 정보가 담겨있지만 source port # 와 dest port # 이 저장되어있다. (de)multiplexing은 source/dest port # 를 이용하여 수행한다. PC의 정보인 IP는 Network Layer에서 생성되는 Packet 자료구조에서 포함된다.


socket으로 데이터를 전달하는 demultiplexing의 경우 Network Layer가 참고해야할 자료가 TCP/UDP에 따라 나뉘게된다. UDP의 경우는 dest IP/dest Port 가 필요하다. Dest IP/Dest Port가 맞는 PC 및 Socket이 있다면 무조건 정보를 받을 수 있다. TCP의 경우는 connection oriented라고도 불리는데, 연결의 중요성을 뜻한다. 그 이름에 맞게끔, TCP의 경우 demultiplexing 후 socket으로 정상적으로 전달되기 위해선 Dest IP/Dest Port 및 Source IP/Source Port도 필요하다. 허용되지 않은 Source IP 에겐 데이터를 App 계층으로 데이터를 넘기지 않는다.

예를 들어, 네이버와 같은 웹 페이지에 접속하는 경우, 웹 서버는 멀티 쓰레드 환경에서 여러 socket을 제공하고 각 유저에 하나씩 배분해준다.
52분 질문) broad cast 같은 통신 방법에서는 Dest IP가 필요없지 않나? 답: broadcast란 여러사람들에게 데이터를 전달해주는 것인데, 현재 우리 수준에서 대답을 드리자면, 현재 인터넷 환경에서 broadcast는 제공하지 않고있고, 어플리케이션 예로는 카카오톡 단톡방이 있을 건데, 한 명이 채팅치면 여러 명에게 전달되는... 내부적으로 따져들어가면 N 명에게 각각 TCP 연결을 하고 있다.
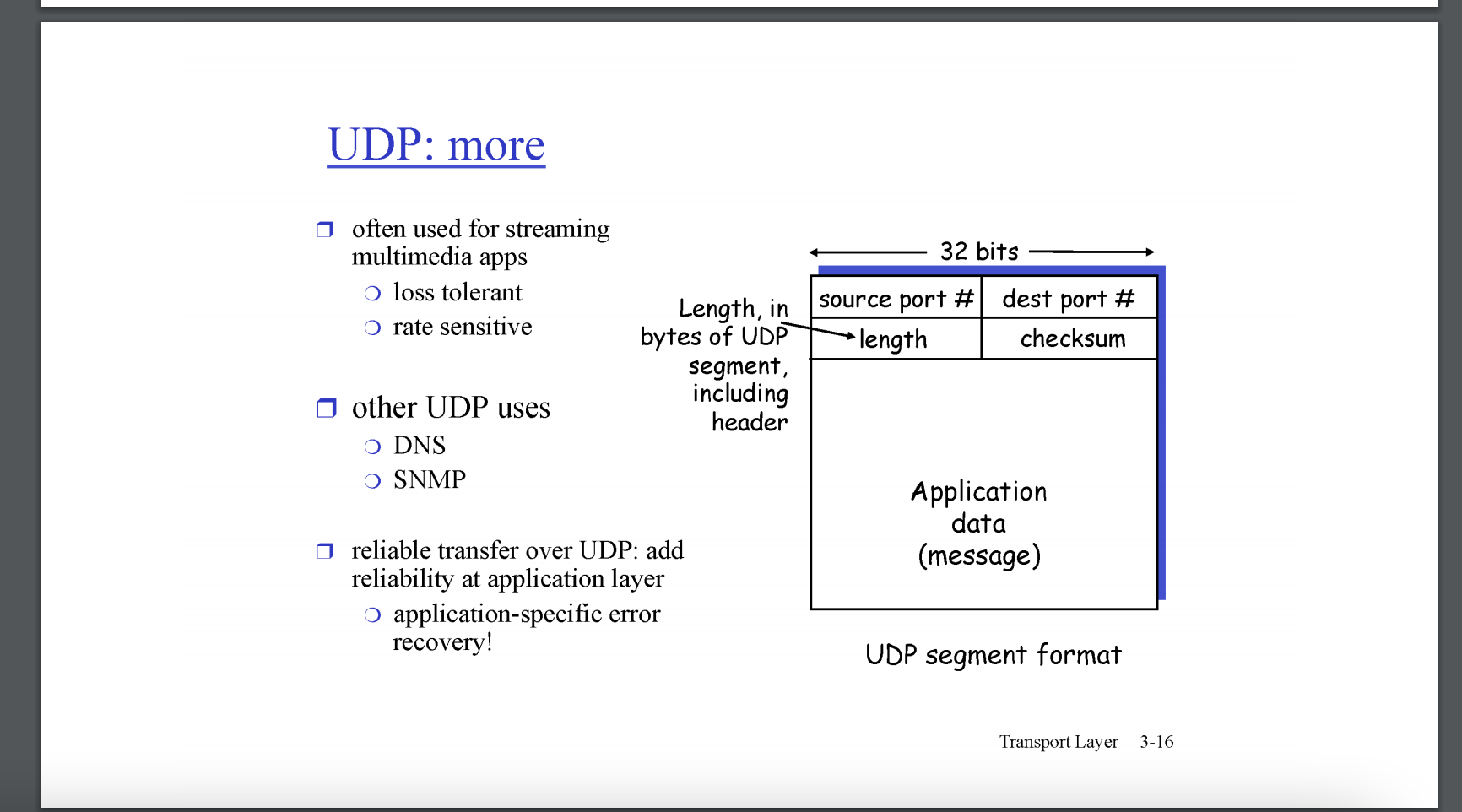
UDP : User Datagram Protocol
UDP는 connectionless의 성격을 띄고있다. segment는 header + data로 이루어져있다. header에는 source port #, dest port #, length, checksum을 가지고 있다. 헤더가 담고있는 프로토콜의 특징을 나타내는데 큰 도움을 준다. 예로, 우편배달부는 편지 내용에 따라 전달방법이 결정되지 않고 봉투에 어떤 정보가 적혀있는가에 따라 편지를 전달하는 방법이 결정된다. UDP는 header의 내용이 간단한데, 간단한 전달 방식을 따른다는 것을 유추해볼 수 있다. source port #, dest port #는 Port 번호인데, multiplexing/demultiplexing을 한다. length는 header를 포함한 UDP Segment의 크기를 알 수 있다. checksum은 전송 도중 segment의 data 내용이 변이되어있는지 검사하는데 사용한다. checksum의 정확한 동작은 검색을 통해 알아낼 수 있으나 넘긴다. checksum을 이용하여 에러를 발견한 경우, Application 계층으로 segment를 넘기지 않고 drop 시킨다.
TCP : Transmission Control Protocol
RDT : Reliable Data Transfer Protocol
아 1시간 30분동안 TCP RDT 부분 작성하고있는데, 다 날라갔네!!!!!!
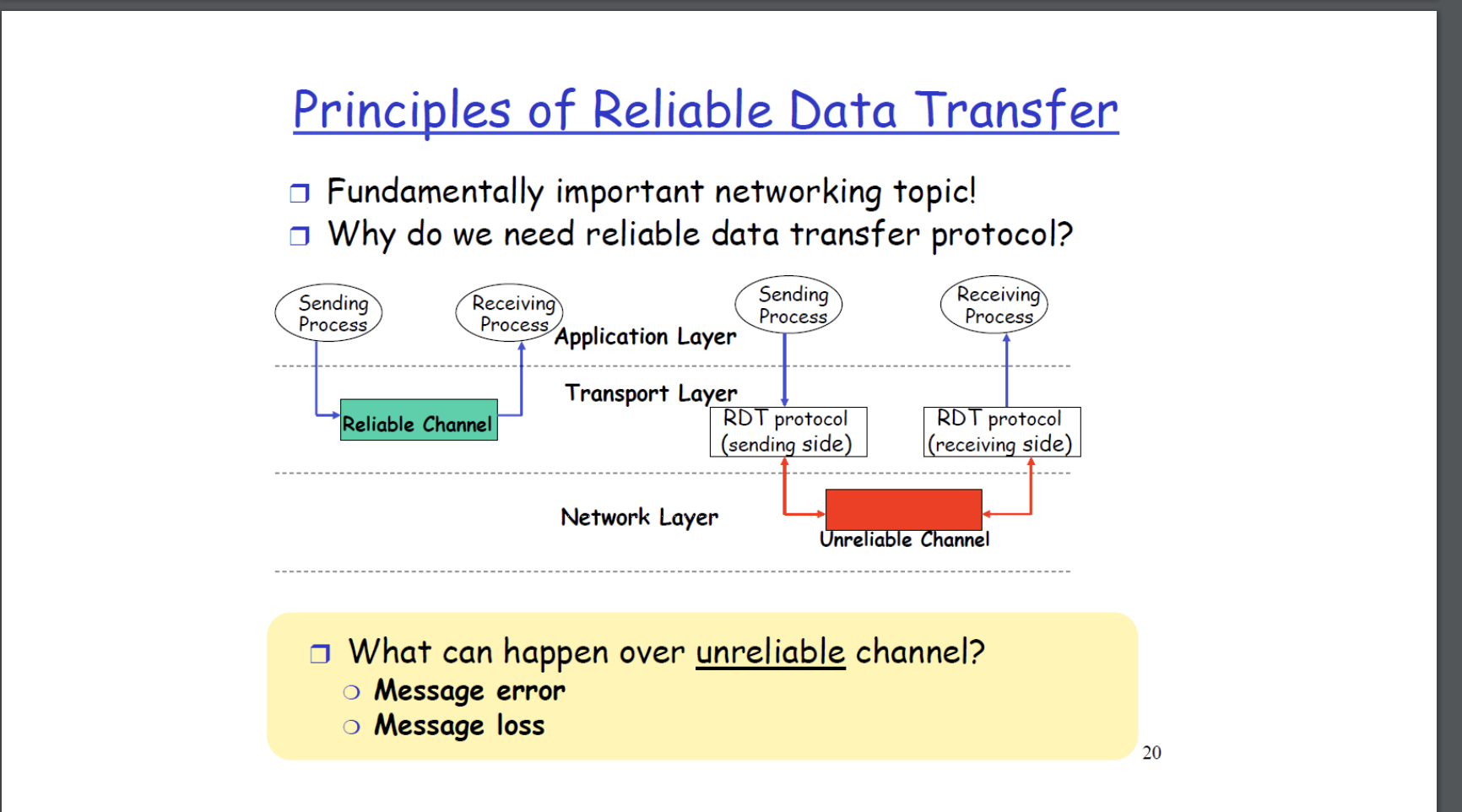
UDP는 (de)multiplexing/error check라는 큰 두 기능을 수행하지만, TCP는 그 보다 더 많은 기능을 제공해준다. reliable, in order delivery 기능등이 있다. 여기서는 큰 특징 중 하나인 reliable에 대해 중점적으로 다룰 거이다. 왜 reliable이란 기능이 필요한 걸까? TCP는 transport 계층에 있는데, 그 하위 계층에서의 동작은 unreliable하다는 특징이 있기 때문이다. 예로 Transport 하위의 계층으론 Network 계층이 있다. 만약 unreliable하다면 어떤 상황이 발생할까? 두 상황이 발생하는데 packet error와 packet loss 상황이 발생한다.
이를 해소하기위해 TCP는 RDT를 구현한다. RDT란 Reliable Data Transfer Protocol 이며 TCP는 RDT의 기능을 포함한다. 신뢰가능한 데이터 전송 프로토콜이 되려면 어떤 것이 가능해야할까? RDT가 제안하는 큰 흐름을 간단하게 표현하면 한 패킷을 전달해준다음, 전달해준 한 패킷에 대하여 잘 전달받았다는 feedback을 이용하여 reliable을 제시한다.

지금부터는, 단계적으로 상황을 제시하며 점차 고도화된 RDT를 이야기해볼것이다. 지금부터 RDT의 설명을 돕기위해 STOP-AND-WAIT Protocol을 전제로 Finite State Machine을 이용하여 설명할 것이다. 만약 하위 계층에서 packet loss나 packet error가 발생하지 않는다면 RDT의 동작은 매우 간단할것이다. 아래는 sender, receiver RDT의 FSM이다.

RDT는 sender, receiver에서 어떠한 동작도 수행할 필요가 없다. sender에서는 상위 계층에서 data를 전달해달라는 call이 오면 하위계층으로 data로 부터 packet을 만들어 전달하면되고, receiver는 하위 계층으로부터 packet이 들어왔다는 call이 오면 packet으로부터 data를 추출하여 상위계층으로 data를 전달하면 된다.
만약 하위 계층에서 error를 발생시킨다면 RDT는 어떠한 요구사항을 충족해야할까? 우선적으로 error를 검출해야하는 error detection을 수행해야한다. 앞서 UDP에서도 error detection을 수행하는데, checksum을 활용하여 error detection메커니즘을 수행한다. RDT도 마찬가지이다. 하지만 RDT의 경우, error detection이 있다면 sender로 부터 재 전달을 받아야한다.

RDT는 Feedback이라는 개념을 활용한다. sender는 receiver로 부터 error의 여부에 따라 "ACK" 또는 "NAK"을 전달받는 형태로 동작하고 만약 "NAK"을 전달받은 경우 Retransmission을 수행한다. 이런 절차를 통해 reliable 특성을 만족시킬 수 있다. 큰 절차는 Error detection, Feedback(ACK/NAK), Retransmission이다.
아래는, error가 있을 경우의 RDT의 FSM을 표시한것이다.

sender RDT는 상위계층으로부터 call을 대기한다. 만약 상위계층으로부터 data를 전달받으면, data와 checksum을 활용하여 packet으로 만들고 전달한다. 그리고 ACK 또는 NAK feedback을 대기한다. 만약, packet을 받고 NAK feeback을 포함하고 있다면 다시 packet을 전달한뒤 ACK 또는 NAK feedback을 대기한다. 만약 packet을 받았고 ACK feedback을 포함하고 있다면, 상위 계층으로부터 call을 대기하는 상태로 이동한다. receiver RDT는 하위계층으로부터 call을 대기한다. 만약 하위계층으로부터 packet을 전달받으면, packet에 대해 error detection을 수행한다. 그리고 error가 있다면 NAK feedback을 포함한 packet을 전송하고, 아래 계층으로부터 call을 대기한다. 만약 error가 없다면, packet으로부터 data를 추출하고, 상위계층으로 data를 전달하고, ACK feedback을 포함한 packet을 전송한다.
이를 이용하여 모든 문제가 해결되지 않는다. receiver RDT가 반환하는 ACK/NAK feedback 자체가 coorupt된 상태일수도 있기 때문이다. 그래서 sender는 NAK feedback이 에러거나, checksum을 활용한 error detection 메커니즘을 활용하여 feedback이 corrupt 된 경우 packet을 재전송한다. 문제는, 재전송된 packet이 그 다음 절차의 packet인지, 재전송된 packet인지 receiver로서는 분간이 되지 않는다. packet 발송 메커니즘을 수행하는 sender만이 재전송된 packet인지 그 다음의 packet인지를 알고 있기 때문이다. 그래서 TCP에서는 packet의 header에 packet의 순서를 저장하는(seq #) 필드를 제공해준다.


packet의 헤더에 seq 필드를 제공해주는데 seq 필드의 자료형은 무엇일까? 만약 packet마다 모두 고유한 넘버링을 가진다고 해보자. 첫 packet의 seq 값이 0이라고하고, 네트워크 정보를 계속해서 제공하다보면 만, 십만... 이런식으로 요구하는 자료형이 커질 것이다. 그러다보면 packet이 실질적으로 전달해야할 데이터 영역보다 헤더의 영역이 요구하는 자료형이 더 커질것이고 이는 overhead에 해당한다. 우선 결론부터 이야기하면, seq 필드는 2-bit 자료형이면 충분하다. sender가 seq 0의 pakcet을 보냈을 때, receiver가 정상적으로 받았다면, receiver는 그 다음의 packet의 seq는 1임을 기대할 것이다. 그리고 seq 1을 보냈고 잘 받았다면, 그 다음의 packet의 seq는 0임을 기대할 것이다. 아래는 seq을 같이 표현한 sender-receiver간 네트워크 흐름이다.


그러하여 RDT는 packet error를 처리하기위해 Error detection, Feedback, Retransmission, Seq #을 지원한다.
차기 RDT에서는 Nak-free로서 sender가 packet을 받으면 무조건 마지막으로 자신이 정상적으로 받은 Seq #을 포함한 ACK packet을 보낸다. receiver는 자신이 최종적으로 보낸 packet의 seq #을 기준으로 sender가 보낸 ACK packet의 seq #을 비교하여, ACK NAK 상황인지 판단하고 Retransmission을 할지 다음 packet을 보낼지 판단한다. 아래는 NAK-free의 예다.

RDT에서 packet loss는 어떻게 해결할 수 있을까? packet loss란 packet을 보냈는데 receiver가 아무것도 받지 않아 어떠한 feedback도 보내지 못하는 상황인 것이다. RDT는 sender에 packet을 전송함과 동시에 내부에서 timer를 수행하여 timer가 허용하는 시간동안 feedback을 받지 못하면 retransmission을 수행한다.

아래의 그림은 sender와 receiver 간에 수행되는 timeout을 포함한 packet 전송이다.
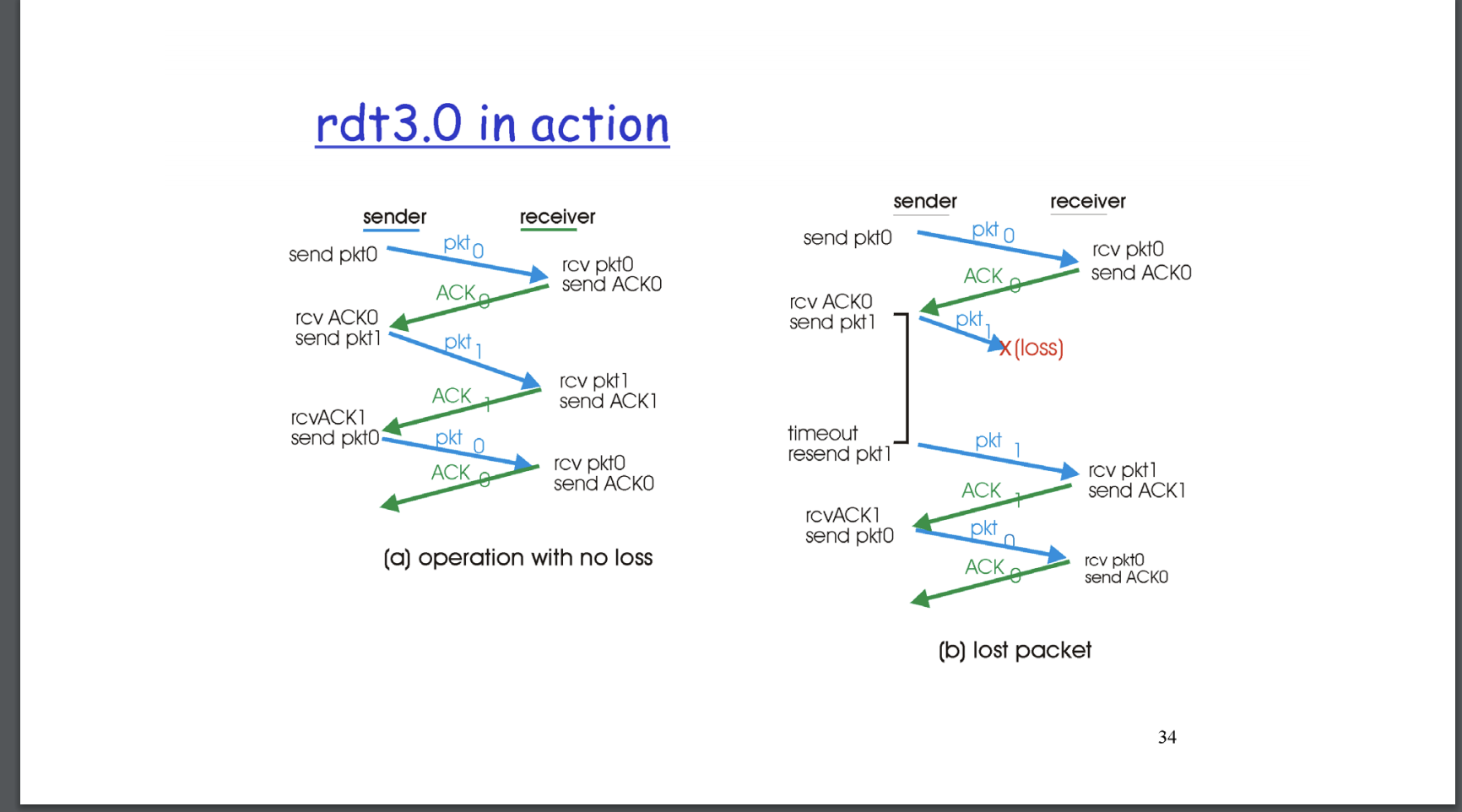

그림 d에서는 timeout이 발생(packet이 여러 route를 거쳐 전송이 늦었거나, timeout이 너무 짧은 등의 문제로)하여 진행되는 그림을 보여준다. timeout이 발생한 뒤, 재 전송된 pkt1을 보면 receiver에서는 그것을 받아 duplicate packet을 버리게 될 것 이다. timeout이 너무 많이 발생하게되면 receiver, sender는 서로 네트워크상에서 duplicate된 packet을 여러번 전송할 것 이다. 현재의 학습 수준에서는 receiver에서 duplicate한 패킷을 정상적으로 처리를 해준다는 전제를 하여 문제는 없지만, 이러한 문제가 현실에서 발생하게되면 문제가 있을 것이다.
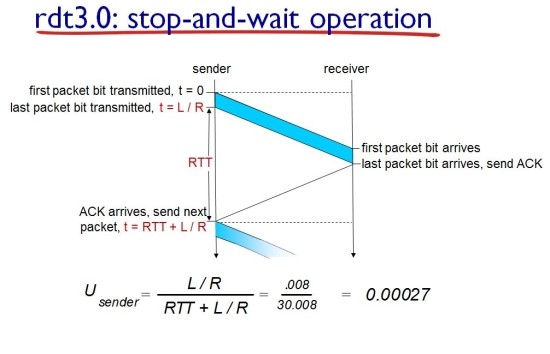
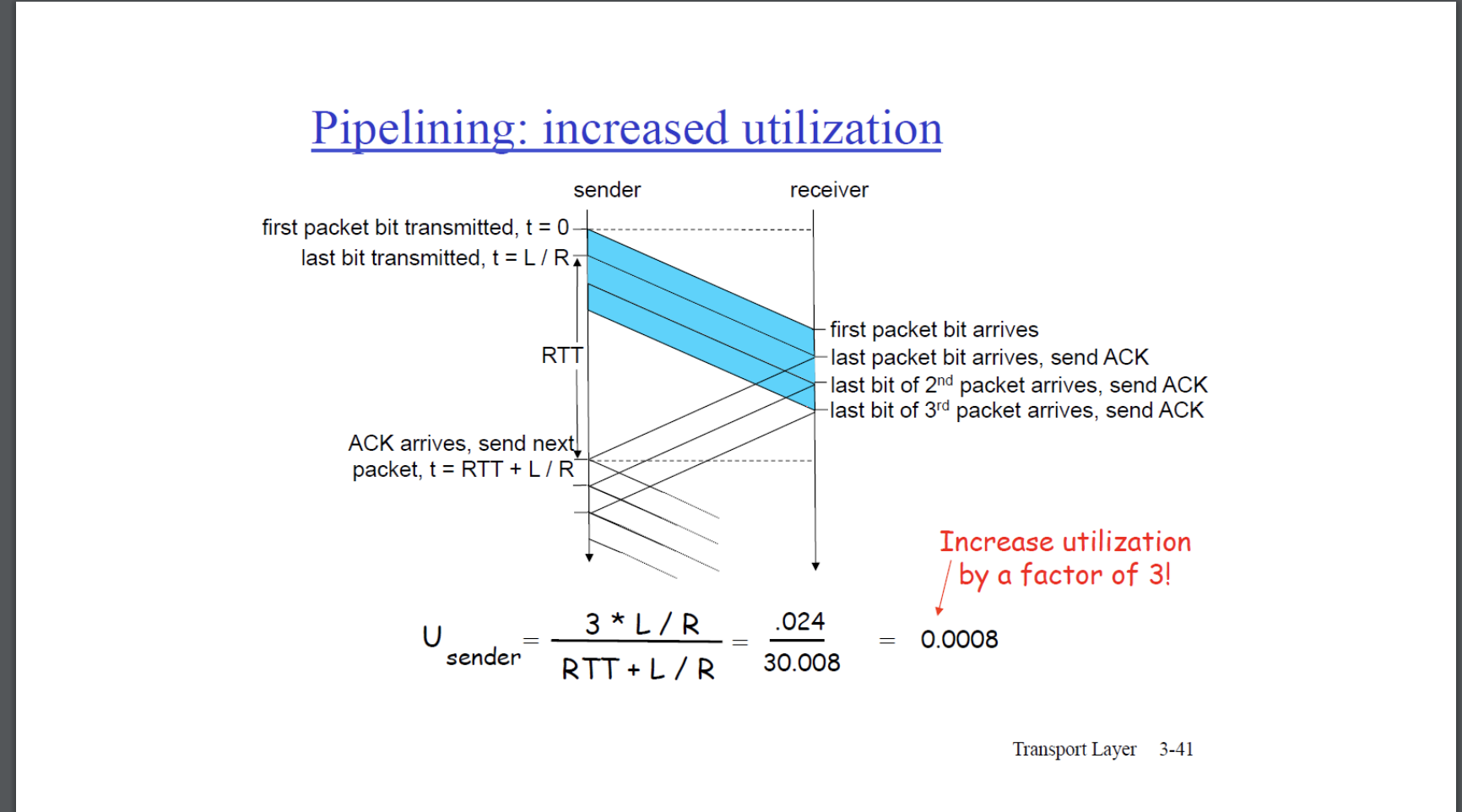
논리를 진행하면서 rdt 3.0까지 보여주었다. 여기까지의 설명으로 rdt3.0은 packet loss & error에 대해 알아보았다. 이제 rdt 3.0의 성능에 대해 이야기해보려고한다. rdt의 기본 전제는 Stop and Wait protocol으로서, 한 패킷을 전송하고 feedback 패킷을 대기한다. 이는 알고리즘 때문에 물리 네트워크 상의 적절한 resource를 제대로 사용하지 못하고, 제한하는 것과 같다.
아래는 rdt 3.0의 성능을 보여준다. rdt3.0에서는 Transmission에 소요되는 시간 + RTT란 시간이 추가적으로 소요되는데, RTT란 feedback이 오는데에 sender가 기다리는 시간이다. RTT를 통해 packet loss & packet error의 문제를 해결하지만, 해당 문제를 해결하는 여유있는 시간을 전제로해야기 때문에 Transmission보다 RTT는 굉장히 큰 상수로 설정된다. Utilization이 굉장히 낮다는 것이 문제이다.

Pipelined Protocols
현재의 TCP에서는 한번의 전송에서 하나의 packet을 보내지 않고, 여러 packet을 pipeline을 통해 왕창 보내는 식으로 성능 문제를 개선한다.
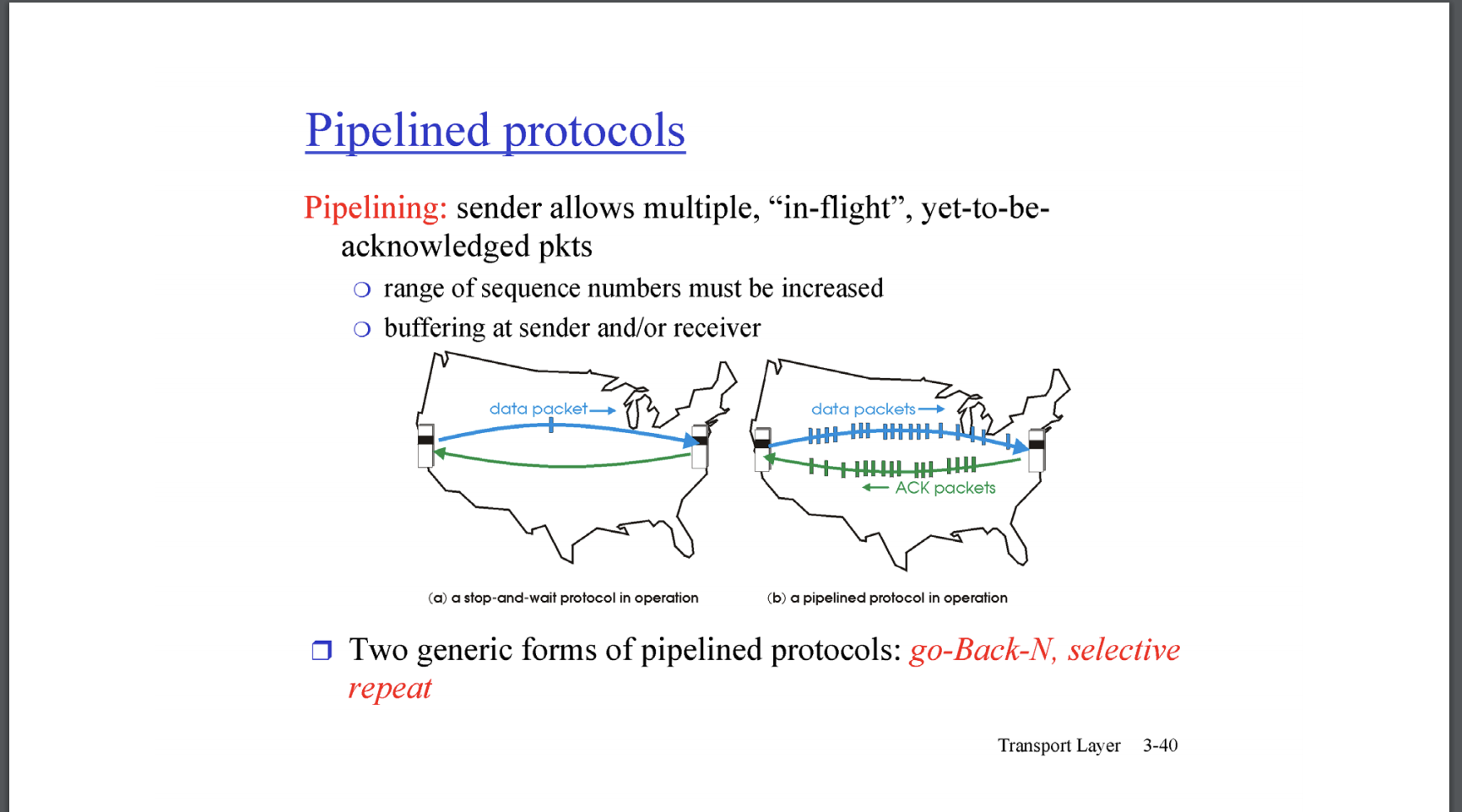
pipeline의 개요는 위의 그림과 같다. sender는 data packet을 왕창 보내고, receiver는 ack packet을 왕창보낸다. 이로써 Utilization을 높일 수 있다. pipeline 방식으로 신뢰성있는 전송을 위해서는 go-Back-N, selective report를 제공해야한다.
Go-Back-N
Go-Back-N은 windows size를 정하여 해당 수만큼의 packet을 전송한다. windows size란 feedback을 받지 않고 보낼수 있는 허용된 packet 숫자이다. 전송되는 packet의 크기가 다르므로, ACK(n)이란 개념이 등장한다. RDT에서 ACK(n)이란 seq# n번의 packet을 잘 받았다는 응답이지만, Go-Back-N 에서의 ACK(n)이란 n개의 ACK을 잘 받았다는 응답이다. 만약 feedback을 timer의 시간내로 받지 못하였다면 N사이즈의 packet을 전부 재전송한다.


위는 Go-Back-N(GBN)의 FSM이다.
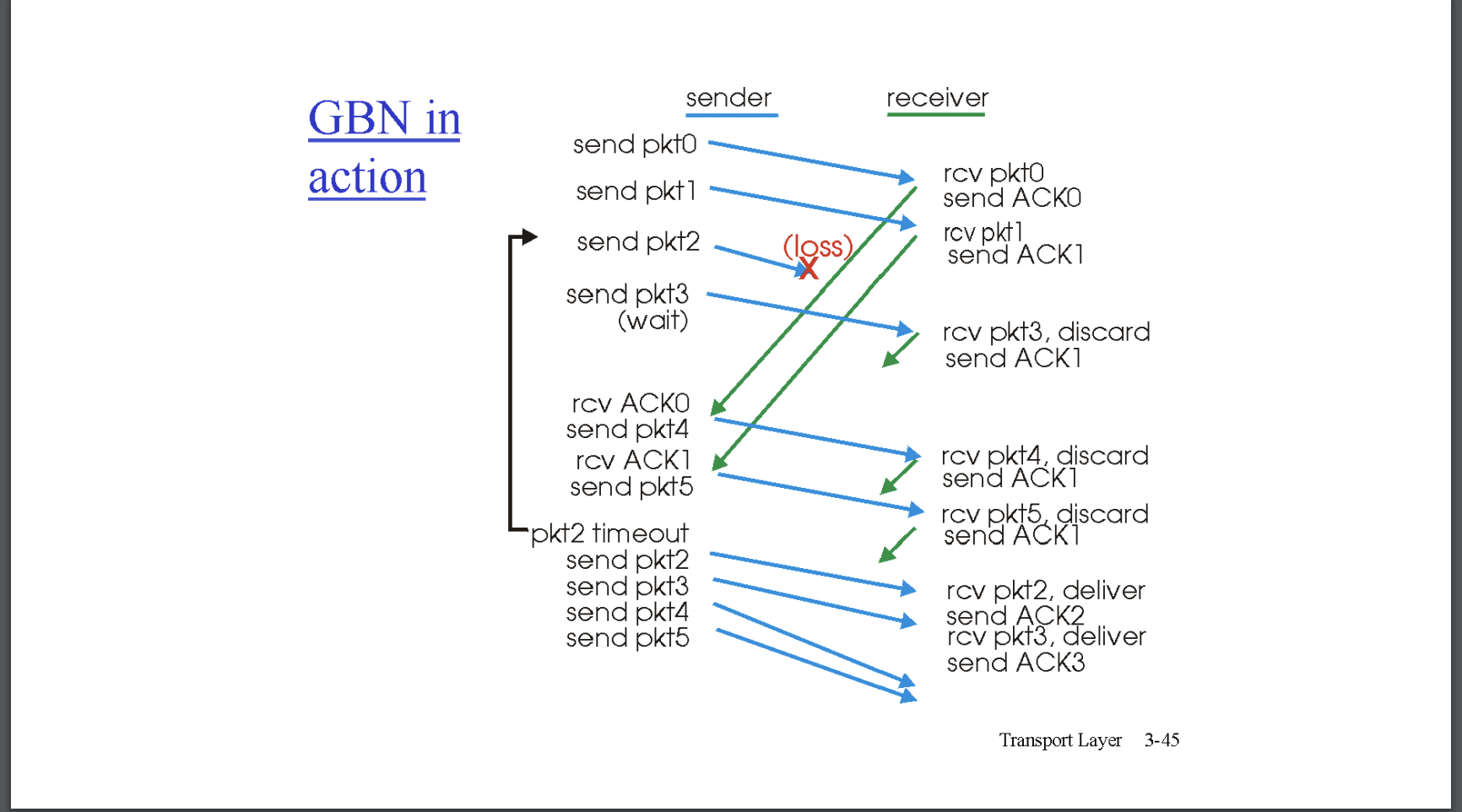
위는 windows size가 4인 GBN 상에서 sende와 receiver가 수행하는 행동을 보여주는 그림이다. send pkt2에서 pkt2가 loss가 되었다. 그 후에 다른 seq #의 pkt이 도착하더라도 receiver는 무조건 discard하며 이전까지 제대로 받은 packet의 seq을 포함한 ACK feedback을 전달한다. sender는 receiver로부터 ACK 0, ACK 1을 받았으므로, windows size에 포함된 packet이 다음과 같이 변화된다. [0, 1, 2, 3] => [2, 3, 4, 5] 그런데 전달된 2에 대한 ACK은 받지 못하고 전송한 3, 4, 5에 대해 ACK 1을 받았을 수 있고 아직 전달받지 못하였을 수도 있다. 결국엔 pkt 2에 대해 어떠한 feedback 도 받지 못하였으므로(loss) windows size에 대해 전부 재전송하게된다. [2,3,4,5]
만약 어떠한 packet error, packet loss가 없는 이상적인 상황이라면, sender에서는 [0,1,2,3] => [4,5,6,7] => [8,9,10,11] 식으로 packet windows를 이동하며 전송할 것이다. sender의 입장에서는, windows size안에 있는 packet을 재전송할 염려가 있기 때문에 buffer에 올려놓고 있어야한다.
Selective Repeat
GBN에서는 error나 loss가 발생한 seq#의 packet부터 N개의 packet을 모두 재전송한다. 이를 조금 더 개선한 방식인 Selective Repeat은 sender는 ACK을 받지 못 한 선택적인 packet에 대해서만 연속적으로 받는 것을 제시한다. 여기서 ACK(n)은 seq #n을 잘 받았다는 feedback으로 표현한다.


위 그림은 Selective Repeat상에서 sender와 receiver의 연속적인 packet windows를 표현한다. GBN에서는sender만 상태를 가졌지만, Selective Repeat에서는 sender와 receiver는 서로의 packet state list를 갖게된다. 그리고 GBN은 ack-yet acked인 불연속면이 단 한군데에 존재하지만, Selective Repeat에서는 ack-yet ack인 불 연속적인 면이 여러 군데에서 갖게된다.

위 예에선 packet 2번이 loss가 난다. packet 2번이 loss나기 전의 packet인 pkt0, pkt1에 대해선 receiver는 Application Layer에 deliver한다. pkt2가 timeout 나기 전까지 sender는 windows size에 포함될 수 있는 packet을 연속적으로 전달한다. 만약 특정 packet에 대해 timeout이 발생한다면, 해당 packet만을 재전송한다. receiver는 손실된 packet을 정상적으로 전달받으면, 순서대로 packet을 정리하여 application layer에 전달한다. GBN에 비해 Selective Repeat에서는 Receiver가 가져야할 책임상, 메모리 상의 요구사항이 있다.
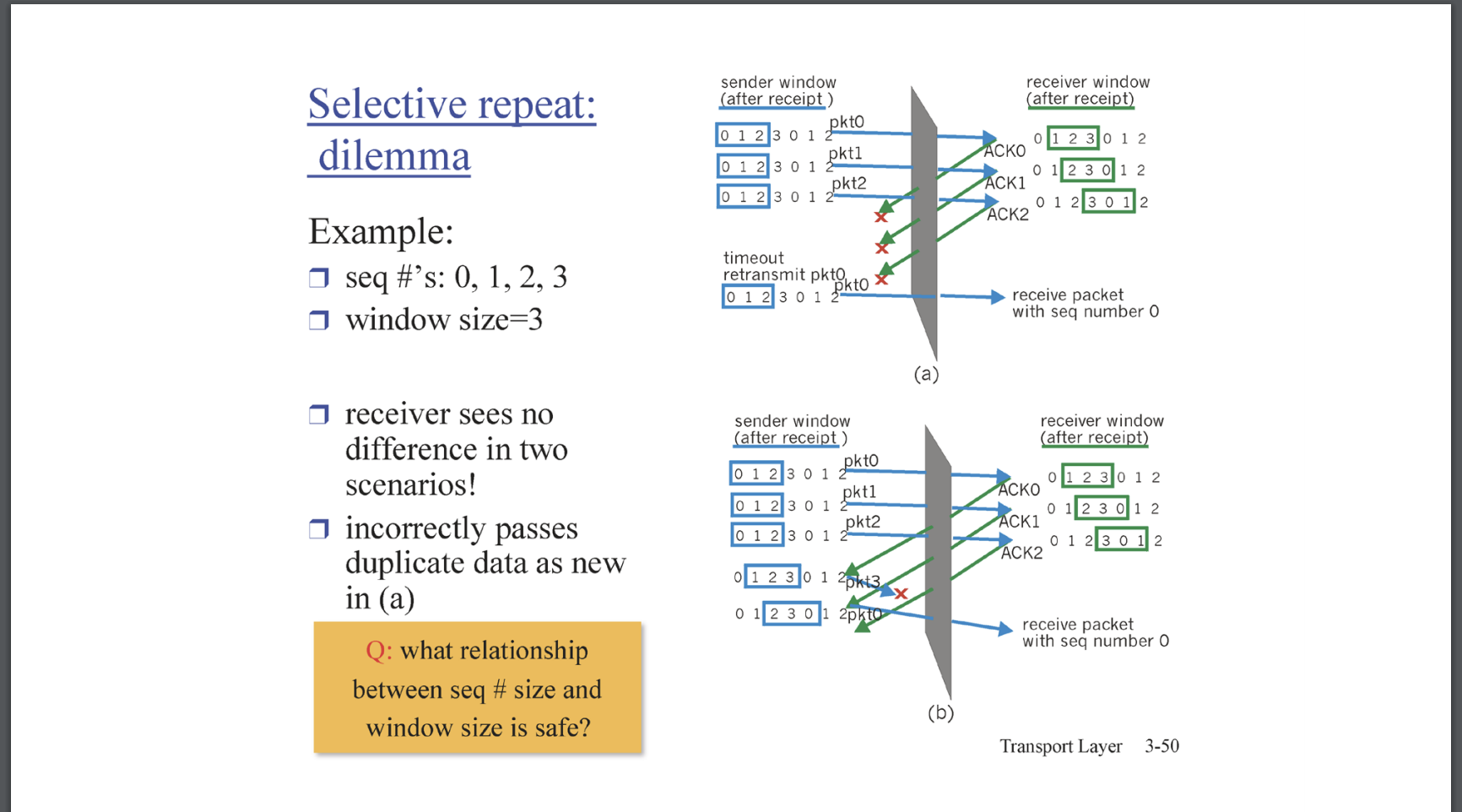
Selective Repeat에서도 seq # 필드의 자료형이 요구된다. 위 예는 windows size가 3이고 seq #가 4인 상황에서 가질 수 있는 딜레마를 보여준다.
만약 windows size가 3이고, seq가 0,1 ,2, 3 이라고하자. 시작으로 sender 는 seq 0,1,2를 넘버링한 packet 0,1,2을 전송한다. receiver는 pkt 0,1,2를 모두 정상적으로 받고, application layer에도 전달하고, ACK(0), ACK(1), ACK(2) 패킷을 전송한뒤, 메모리상에서 seq 3,0,1의 3개 패킷을 위한 자리를 만들어(buffer) 기다리는 상황이라고 하자. 그런데 receiver가 전송한 ACK이 모두 유실되었다고 하자. 그러면 sender는 receiver에게 seq 0,1,2를 넘버링한 pkt0, pkt1, pkt2를 다시 재전송한다. 이 때, receiver는 그 seq # 3,0,1로 넘버링된 그다음 차례의 packet을 기다리고 있는데, 재전송된 seq 0을 받는다. 이때 receiver는 0이 재전송된 packet인지 그다음 차례의 0인지 판단할 능력이 없다.
그래서 seq size와 windows size은 N+1:N으로 설정될 수 없다. seq size:windows size를 최소화하는 수는 대충 n*N:N으로 할수 있다. 조금 더 생각해보면, n은 2가 될 수 있다. seq size는 windows size의 2배면 충분하다.
Selective Repeat의 방법에도 단점이 있다. windows size안에 있는 모든 packet에 대해 timer를 수행해야하며, 그로 인해 computer resource가 소모되어야 한다는 점이다. computer 상에 네트워크를 사용하는 프로세스가 하나만 동작하는 것이 아니므로, resource 소모량이 매우 크다는 단점이있다.
다음 포스팅에서는 TCP에서 어떻게 이 방법을 해소하는지 다루어 볼 것이다.
'네트워크' 카테고리의 다른 글
| HTTP 정리 (0) | 2021.06.17 |
|---|---|
| 중간 과제) socket 프로그래밍 (0) | 2021.05.15 |
| 인강 ) 전송계층(3) - TCP(2) (0) | 2021.05.05 |
| 인강 ) 전송계층(2) - TCP (0) | 2021.05.04 |
| 인강) 컴퓨터 네트워크 기본 2 (0) | 2021.04.10 |
- Total
- Today
- Yesterday
- 아레나
- 최단경로 알고리즘
- 아레나시뮬레이션
- Discrete Mathematics
- 엄청난 인내심과 시뮬레이션을 위한 아레나 툴
- 이산수학
- javascript
- 이산 수학
- 자바스크립트
- 데이터 중심 애플리케이션 설계
- flutter
- 자바스크립트 예제
- paul wilton
- 대규모 시스템 설계 기초
- 그라파나
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- Arena
- Trie
- 명제논리
- Propositional and Predicate Logic
- grafana cloud
- arena simulation
- Simulation
- rosen
- 시뮬레이션
- beginning javascript
- 로젠
- 조합 코딩
- 백준
- 아레나 시뮬레이션
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |